La bible du
MAILLAGE INTERNE
Liens internes = levier de référencement le plus puissant que vous maîtrisez à 100 % après le contenu.
Ce guide regroupe les concepts, méthodes & stratégies de maillage pour améliorer votre SEO en 2025
Avant la lecture de ce guide

Incapacité à diagnostiquer les erreurs de maillage prioritaires
Difficulté à choisir son modèle de maillage interne
Impossible de choisir la direction de ses liens internes
Ancrages internes non optimisés et anti ROI
Méthode de maillage fouillie ou inexistante lors de la création de contenu
Après la lecture de ce guide

Identifier et corriger les erreurs de maillage rapidement
Sélection stratégique du modèle de maillage adapté à vos objectifs SEO
Maîtrise complète de la direction des liens internes pour un parcours utilisateur optimisé et un glissement sémantique optimal
Ancrages internes diversifiés et optimisés pour un ROI maximal
Process de maillage fluide et pertinent lors de la création de contenu et méthode de remaillage simple
Les bonnes pratiques du maillage interne ont considérablement évolué ces dernières années. L’époque où il suffisait de multiplier les liens est révolue.
Aujourd’hui, Google analyse (plus ou moins) finement la cohérence sémantique de vos liens et leur pertinence pour l’utilisateur.
Ce guide, que dis-je, cette bible fait le point sur les nouvelles approches du maillage interne en 2025, en s’appuyant sur les dernières études et retours d’expérience de la communauté SEO.
Dès que l’on débute le SEO, on apprend que le contenu est important. Mais écrire des contenus pour alimenter son site internet n’est que le niveau 1.
Maitriser le maillage interne permet d’accéder à une boucle vertueuse :
➜ Un bon maillage permet d’augmenter le ROI de vos contenus,
➜ donc d’y mettre plus de ressources et augmenter la qualité,
➜ ce qui va augmenter votre conversion et vos revenus.
Alors comment capitaliser sur ces contenus ? Comment faire connaître les pages qui favorisent la conversion ? Combien de liens placer ? Quelles ancres utiliser ? Comment éviter la dilution du PageRank ?
À travers ce guide, vous allez découvrir des tips concrets et actionnables pour faire passer votre maillage au niveau supérieur.
Cette bible du maillage interne est composées de 4 parties distinctes (et 1 à venir) :
1 – Les définitions à connaître si vous débutez
2 – Détections et corrections des erreurs qui tuent votre maillage à petit feu
3 – Comment optimiser le maillage d’une page spécifique ?
4 – Les différents modèles de maillage interne
5 – Comment optimiser le maillage à l’échelle d’un site existant ? – à venir si ce dossier vous plait

Les définitions et notions à connaître si vous débutez
La majorité d’entre vous sont déjà familiers avec les termes majeurs du maillage interne.
Néanmoins pour bien comprendre chacune des parties suivantes, il est important de partir des mêmes bases.
Voici dans l’ordre de difficulté croissant les notions à saisir :
Qu’est-ce qu’un lien interne ?
Les liens internes sont des liens (appelés hyperliens) qui pointent vers des pages du même domaine. Ils diffèrent des liens externes, qui renvoient à des pages situées sur d’autres domaines.
Il existe différents types de liens internes. Par exemple, ceux qui figurent dans vos menus de navigation et ceux que vous incluez dans votre contenu. Nous reviendrons sur l’importance de chacun d’entre eux.

Qu’est-ce que le maillage interne ?
Le maillage interne est l’ensemble des liens hypertextes, qui vont relier les différentes pages d’un même site web.
Même si techniquement un lien externe est la même chose qu’un lien interne, ils ne sont pas traités de la même manière par les moteurs. Les stratégies d’optimisation sont donc différentes.
Vos choix de maillage interne contribuent à une meilleure structure de votre site et à une optimisation de la diffusion du PageRank entre vos pages.
Et pour vos visiteurs c’est une meilleure expérience utilisateur. Cela a un double impact positif :
- meilleurs signaux utilisateurs ;
- meilleure rentabilité.

Qu’est-ce que le PageRank ?
Le PageRank est l’algorithme à la base de l’hégémonie de Google. C’est ce système qui fait que Google est Google, et non Yahoo ou Bing…
Ce concept permet de mesurer la popularité et l’importance d’une page web en fonction des liens qui pointent vers elle.
Concrètement, il évalue la « valeur » d’une page en fonction de la quantité et de la qualité des liens qu’elle reçoit.
Pour bien comprendre le concept, retenez que le PR est la probabilité qu’un surfeur aléatoire se trouve sur une page donnée à un moment donné.
Dans ce guide, nous nous concentrerons sur le PageRank interne (PRi).
Si vous souhaitez creuser ce point, vous pouvez tester notre simulateur de diffusion du PageRank interne et lire les explications techniques présentées.

Les ancres de lien et leur importance
L’ancre de lien (anchor text en anglais) est le texte cliquable d’un lien hypertexte visible sur une page web.
Olivier Duffez, à travers son étude My Ranking Metrics, a démontré que chaque lien interne contribue à améliorer le positionnement de la page cible sur des requêtes proches ou identiques à l’ancre utilisée.
De son point de vue, pour maximiser cet impact, il est essentiel de diversifier les ancres afin de cibler une large variété de mots-clés tout en conservant un aspect naturel.
Pour le prouver, des données calculées sur 24 millions de pages ont permis d’analyser le nombre d’ancres distinctes reçues par ces pages dans leurs liens internes entrants.
Les résultats obtenus sont les suivants :
Nombre moyen de visites générées via Google sur 30 jours (donnée extrapolable), selon le nombre d’ancres distinctes dans les liens entrants internes follow de la page (seule la 1ère ancre est prise en compte)
Etude réalisée en septembre 2024 par la plateforme My Ranking Metrics (outil RM Tech) sur 24 millions de pages (de +8 000 sites) et 3,8 milliards de visites organiques Google

Les pages avec au moins 11 ancres distinctes dans leurs liens entrants internes génèrent 13 fois + de visites SEO que celles avec une seule ancre.
La variation d’ancre dans les contenus est donc importante pour 2 points :
- Augmenter les chances de positionner une page sur des mots-clés secondaires liés à votre thématique ;
- Utiliser de trop nombreuses fois des liens sur une même ancre est inutile, Google finit par ne plus le prendre en compte. Pour vous donner un ordre d’idées, dès lors qu’il y a une trentaine de liens sur une même ancre, il faut utiliser d’autres ancres sur vos liens internes.
Maintenant que le minimum vital est passé en revu, passons aux erreurs les plus courantes.
Cette section est imposante mais après sa lecture vous serez incollables sur le sujet.
Chaque partie reprend une erreur et explique en quoi c’est problématique, expose un ou plusieurs moyens pour la diagnostiquer et comment la corriger.

Détection et correction des erreurs communes en maillage interne
À moins d’avoir un site complètement neuf ou mono-page, vous avez probablement déjà mis en place des liens internes.
Pour créer une stratégie de liens internes solide, vous devez d’abord comprendre votre structure de liens internes actuelle. Un audit de ces liens peut vous aider.
Cette section liste les problèmes possibles et les méthodes pour identifier et résoudre ces erreurs.
Démarrons avec la plus subjective et la plus souvent oubliée.
Erreur n°0 : ne pas intégrer des CTAs de différents niveaux
La première erreur est de l’ordre de la conversion.
L’oubli des CTA adaptés aux différents stades de réflexion des visiteurs est l’erreur la plus fréquente en maillage interne.
Une page éditoriale bien conçue doit non seulement informer, mais aussi orienter le lecteur vers une action cohérente avec son niveau d’engagement.
Ajouter au minimum 1 CTA pour chaque niveau d’engagement permet de maximiser le potentiel de chaque page.
Pour ne pas complexifier inutilement la chose, je considère 3 ou 4 niveaux de lecteur.
| Type de lecteur | Proximité avec l'achat | Niveau d'implication | CTA principal |
|---|---|---|---|
| Décisionnaire | Très élevée | Élevé | Acheter le produit |
| Convaincu en attente | Moyenne à élevée | Faible à moyen | Obtenir un code promo par email |
| Évaluateur | Moyenne | Élevé | S’inscrire à un programme email ou télécharger une ressource |
| Explorateur | Faible | Faible | Cliquer sur un lien pour plus d’informations |
Pour illustrer cela en pratique, prenons le cas d’un article intitulé « Quelle whey protéine choisir pour le vélo de route ? ». Cet article attire un large public, allant du simple curieux au sportif prêt à acheter.
❌ Cas le plus courant : CTA unique mal ciblé
L’article ne contient qu’un CTA direct vers une page produit :
👉 « Achetez notre whey spéciale cyclisme ici ! »
Problème :
- Un lecteur en phase de découverte (Explorateur) quitte la page sans cliquer, car il voulait juste comprendre les bénéfices de la whey.
- Un lecteur en phase d’évaluation (Évaluateur) aurait aimé accéder à une comparaison détaillée avant d’acheter, mais ne la trouve pas.
- Le Convaincu en attente sait qu’il cherche cette whey mais ce n’est pas urgent, il manque donc un déclencheur.
- Seul le Décisionnaire clique sur le CTA, limitant le taux de conversion.
✅ Ce qu’il faudrait : CTAs adaptés aux stades de réflexion
Un article parfait propose plusieurs portes de sortie adaptées au lecteur :
- Explorateur : Lien vers un article détaillé sur les bénéfices de la whey pour les cyclistes ou un cours par email sur la nutrition en vélo.
- Évaluateur : Un lien pour télécharger un comparatif des meilleures wheys avec tableau des valeurs nutritionnelles.
- Convaincu en attente : Inscription à une newsletter avec code promo pour un premier achat.
- Décisionnaire : Bouton direct vers la page produit.
Résultat : chaque lecteur trouve un CTA adapté à son niveau d’engagement, réduit le taux de rebond et augmente les chances de conversion sans forcer la main.
L’optimisation du maillage interne devient alors un levier direct de performance commerciale.
Pour la mise en place, deux approches sont possibles :
- Intégrer les CTA dans la stratégie de maillage : en liant stratégiquement les pages entre elles selon la maturité du lecteur, on favorise une progression naturelle dans son parcours d’achat (ex. d’un article informatif vers une page produit ou une landing page de conversion).
Cela demande un peu plus de travail en amont pour inclure cette réflexion sur le chemin de conversion, mais la mise en place en aval est plus simple.
- Obfusquer les liens des CTA : si les pages de capture ne sont pas intégrées directement dans le plan de maillage, on peut masquer les liens pour éviter de diluer notre PRi. Cela fonctionne même si le CTA renvoie simplement sur une page contact !
Nous pourrons proposer un dossier spécial sur l’obfuscation si besoin.
Optimiser ses CTA dans le maillage interne, c’est s’assurer que chaque visiteur trouve une porte de sortie adaptée à son état d’esprit, sans forcer un passage prématuré à l’achat.

L’idéal est d’avoir en permanence une porte de passage à l’action visible. C’est plus compliqué sur mobile, mais essayez de les répartir intelligemment tout au long du contenu.
L’idée principale est d’adapter la répartition des CTA au fil de la page, en fonction du niveau d’avancement du sujet et du degré de maturité du persona.
Ainsi on commence toujours par le CTA qui correspond au niveau d’intention principal de la page, puis on ajoute d’autres options au fil de la lecture.
Les autres CTA suivent en ordre décroissant d’engagement, pour ne perdre personne en route.

Prenons un exemple pour une page éditoriale très avancée (persona Décisionnaire ou Convaincu en attente).
➡ Exemple : « Quelle whey choisir pour un cycliste de haut niveau ? »
Ordre des CTA :
- Acheter maintenant (Décisionnaire) → Lien direct vers le produit recommandé.
- Code promo (Convaincu en attente) → « Inscrivez-vous à notre newsletter pour -10% sur votre première commande. »
- Guide PDF comparatif (Évaluateur) → « Téléchargez notre guide complet des meilleures protéines pour cyclistes. »
- Article éducatif complémentaire (Explorateur) → « Découvrez comment optimiser votre récupération avec la nutrition. »
Bien entendu, c’est la théorie, et la pratique nécessite de s’adapter aux réalités techniques du site. Voilà ce que cela pourrait donner sur un site en conditions réelles.

Poursuivons avec la plus classique. Tous les outils de crawl permettent de la faire ressortir, mais pour vraiment progresser en SEO, il faut comprendre POURQUOI c’est un souci.
Erreur n°1 : Les erreurs 404
Les erreurs 404 et la perte de PageRank associée sont l’une des erreurs les plus couramment rencontrées.
Les principaux impacts sont de 3 ordres :
- Perte sèche de PR pour les 404 externes (le plus grave)
- Frustration de l’utilisateur et mauvais signaux qui en découlent
- Augmentation du cost of information retrieval et détérioration de l’image de qualité globale du site aux yeux du moteur
Nous pouvons déjà définir quelques types d’erreurs 404 :
Les 404 internes
Les 404 internes se produisent quand les liens internes de votre site redirigent vers une autre URL du même site qui n’existe pas.

Cela ne concerne pas que les pages HTML.
On trouve régulièrement des 404 associées à des fichiers médias, qui se produisent quand des images ou des fichiers PDF ont été intégrés sur le site, puis ont été supprimés.
2 méthodes pour identifier les 404 internes
Identifier les 404 internes nécessite souvent deux approches complémentaires :
- un crawl par un outil externe
- un complément d’analyse via la GSC
Pour les crawlers externes, il en existe de toutes sortes :
- Screaming Frog,
- Cuik,
- RM Tech
- SemRush et Ahrefs ont une fonction assez similaire d’audit technique,
- Lumar (anciennement DeepCrawl),
- OnCrawl,
- Sitebulb…
Je vous recommande Screaming Frog, car c’est de toute façon le premier outil dans lequel investir. Indispensable à tous les SEO et très peu couteux par rapport aux autres.
Commençons !
Pour la détection des 404 générales sur notre site, il faut tout d’abord trier les liens sur “HTML” pour éviter les images, fichier CSS ou JS notamment.
Ces fichiers en 404 sont également à corriger à terme mais ils ne rentrent pas vraiment dans le cadre de notre opération de maillage interne (et ce guide est déjà imposant).
Commencez par trier les pages HTML :

Sur le même écran, il suffit ensuite de trier le code HTTP par ordre décroissant en cliquant dessus. Nous pouvons voir les 404 présentes sur notre site.
Pour le site de Protéalpes, il y a des 404 sur les images (le tri Screaming Frog ne fonctionne pas toujours) mais rien pour le HTML.

Plus simple, plus direct, plus facile à exporter : nous pouvons faire la même chose pour les liens externes en allant sur l’onglet dédié.

Pour compléter l’analyse, il nous faut aller sur la GSC car toutes les 404 ne sont pas forcément accessibles via un crawl depuis la page d’accueil.
Plusieurs raisons peuvent l’expliquer, parmi lesquelles :
-
Des sites partenaires qui n’ont pas mis à jour leurs liens
-
Des bookmarks d’utilisateurs vers d’anciennes URLs
-
Pages déconnectées de l’arborescence principale
-
Contenu accessible uniquement via d’anciens liens internes supprimés
-
Articles ou produits retirés sans redirection
-
Pages saisonnières ou temporaires non gérées correctement

Notez que vous pouvez sauter l’étape SearchConsole en connectant votre GSC à Screaming Frog.
Une fois les 404 listées commence la partie correction.
Mon hot take sur le sujet est qu’il faut éviter de se reposer sur les 301 pour corriger les 404 internes. Cela ne fait que repousser le problème et ajoute une bille dans notre bocal de dette technique.

Comment corriger ces 404 internes ? (important)
Corriger les 404 internes nécessite 2 actions correctives distinctes :
- Corriger le lien en dur dans le site
- Redirection 301 en sécurité (on y revient)
Pourquoi (et comment) corriger le lien en dur dans la base de données ?
L’objectif est de maintenir une base technique la plus saine possible et de réduire au maximum la complexité d’analyse pour un moteur.
Pour le corriger, je vous conseille d’opter pour un plugin de Chercher / Remplacer en bulk comme Better Search and Replace sur WordPress.
Prenons un exemple :
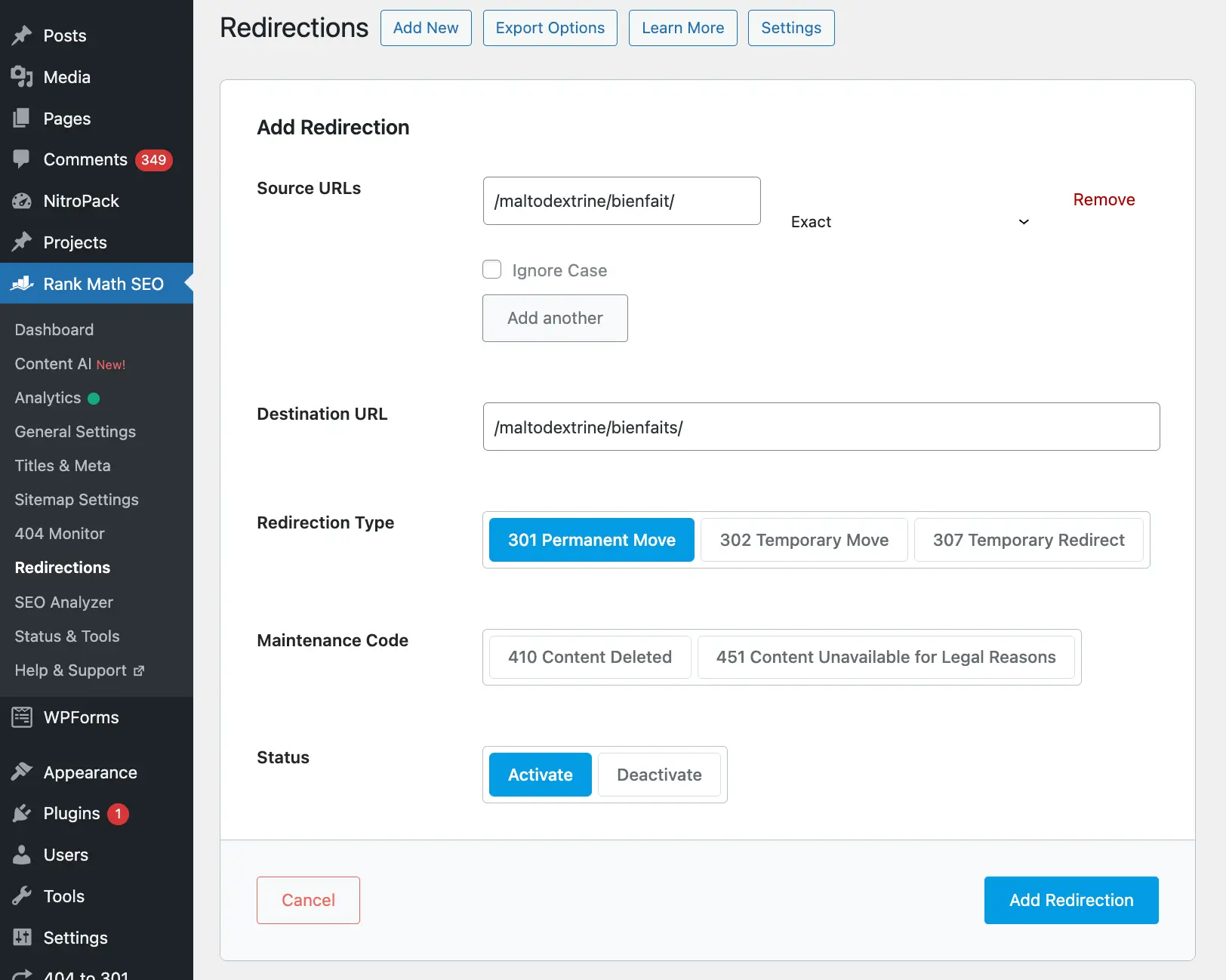
Si j’ai un lien qui comporte une erreur comme cela :
https://protealpes.com/maltodextrine/bienfaits/ est la bonne URL (code 200)
https://protealpes.com/maltodextrine/bienfait/ est en 404 car il manque un « s » à bienfaits
Si l’erreur n’est que sur une page, il est facile d’aller la corriger directement dans le contenu. Cela se complique si le lien est sur plusieurs pages. Pour le savoir, on peut se servir de Screaming Frog. On sélectionne un lien en erreur et on peut voir les pages sources juste en dessous (ici 4) :

Dans ce cas, on peut corriger le lien via le plugin Better Search and Replace en corrigeant directement le lien dans la base de données des pages WordPress. Le principe est le même pour les autres CMS :

Bien, notre lien étant corrigé, on va passer à la redirection 301.
Pourquoi une redirection 301 ?
En très bref, la 301 est une redirection définitive vers la nouvelle URL, là où une 302 déplace de manière temporaire une URL vers une autre.
À priori, quand on corrige une 404, il n’y a pas lieu de revenir en arrière donc la 302 n’a pas de sens.

Notez que la différence d’impact entre les redirections 301 et 302 sur le PageRank est aujourd’hui beaucoup plus nuancée qu’auparavant.
Historiquement (pré-2016), il y avait une différence claire :
- 301 : transfert quasi-total du PageRank
- 302 : peu ou pas de transfert du PageRank
Actuellement, Google annonce traiter les deux types de redirections de manière similaire en termes de transfert de PageRank. Cependant, des différences peuvent subsister dans certaines situations.
- Si une 302 reste en place pendant une longue période (plusieurs mois), Google peut la traiter comme une 301
- Si la 302 change fréquemment de destination, le transfert de PageRank pourrait être moins stable
Revenons à nos moutons 🐏
Même avec la correction en dur dans le site, il y a 2 raisons pour lesquelles il faut tout de même créer des redirections définitives :
- Si Google revient sur la page en question car il l’avait dans son index pour une raison ou pour une autre, il est automatiquement redirigé vers la bonne URL.
- Si par hasard il y avait un backlink vers cette page, le PageRank est redirigé et non perdu.
Comment faire ? Il y a plusieurs façons d’y parvenir. Le plus simple est souvent de passer par un plugin ou par votre hébergeur.
Par exemple sur Kinsta :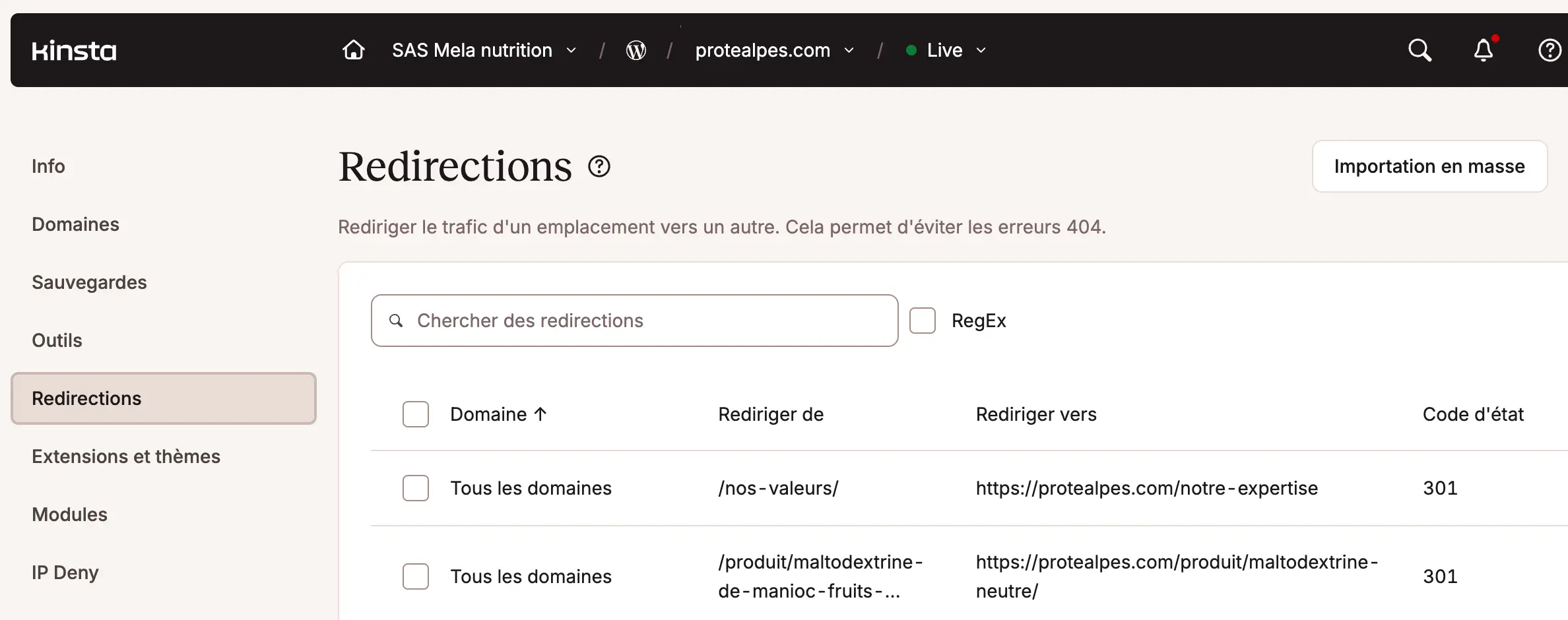
Ou via RankMath :
Les 404 internes-externes
Les 404 internes-externes sont des liens sortants présents sur votre site, et qui redirigent vers des pages ou des sites web externes qui n’existent pas (ou plus).
Les 404 externes n’affectent pas le référencement, mais y’a t-il un transfert inutile du PageRank à une page web inexistante ? Pas vraiment. Pour le détail, c’est juste en dessous 🔽

Selon vous, un lien en 404 vers un site externe vous fait-il perdre du PageRank ?
Pour la réponse, c’est juste en dessous 🔽
Les 404 internes-externes : détail et impact
Imaginons qu’une page A fait un lien vers une page B en code 200 et vers une page C en code 404.
D’un point de vue purement « PageRank », un lien pointant vers une page en 404 est généralement considéré comme un lien mort : il ne transmet pas de « jus » et n’augmente pas la valeur de la page cible (puisqu’elle n’existe pas).
Quant à savoir si cela réduit la part de PageRank transmise aux autres liens (B dans l’exemple), Google n’a jamais donné de déclaration officielle et détaillée.
Deux hypothèses existent dans la communauté SEO :
- Le lien 404 est ignoré et ne rentre pas dans le calcul de répartition ; dans ce cas, la page B reçoit la même quantité de « jus » que si le lien 404 n’existait pas.
- Le lien 404 est comptabilisé comme un lien sortant, et le PageRank est « gaspillé » (perdu) sur ce lien mort, ce qui diminuerait légèrement la part transmise aux liens valides.
À priori la majorité des SEO penchent pour la première hypothèse : Google « ignore » la plupart des liens cassés et ne les fait pas entrer dans la répartition réelle du PageRank.
Plus réalistiquement, l’impact négatif est minime et est surtout lié à deux aspects :
1 – L’image globale du site aux yeux des crawlers est impactée.
2 – Le fait de citer une source fiable et cohérente avec notre thématique est neutre ou positif. Si notre source est en 404, on perd cet avantage.
Voyons maintenant comment les identifier.
Trouver les 404 internes-externes
Le plus simple est sans aucun doute d’aller directement dans l’onglet Screaming Frog relatif aux liens externes. Vous triez ensuite par code HTTP et repérez les codes d’erreur.

Pour la correction, c’est bien simple et ça ne mérite pas une section dédiée : on remplace par une ressource équivalente ou on supprime le lien.
Si vous souhaitez traiter un lien en erreur, pour trouver la page qui fait ce lien il vous suffit de cliquer sur la ligne correspondante comme on a pu le voir dans la section « Comment corriger ces 404 internes ? (important) »
Encore une fois, dans certains cas traiter les liens en bulk peut vous faire gagner beaucoup de temps.
Les 404 externes
Les 404 externes arrivent quand des liens externes (backlinks) pointent vers des pages de votre site qui n’existent pas ou qui ont été modifiées.
Concrètement, la 404 externe est la pire erreur 404 : c’est tout simplement une perte sèche de PageRank.
Et hormis cette perte de jus, c’est l’une des causes d’une chute de trafic après une migration de site, et potentiellement un micro-signal négatif aux yeux du moteur.
Paradoxalement, cette erreur 404 est la plus grave mais aussi la plus souvent oubliée.
Mais comment détecter ces 404 externes ?
➜ Faites un crawl de vos backlinks.
Rendez-vous sur Ahrefs, Semrush ou Majestic, et exportez vos backlinks.

Ensuite, rendez-vous dans Screaming Frog et utiliser le mode Liste pour crawler les URLs exportées.

Utilisez les codes HTTP pour identifier les 404 et isolez ces urls.

Comment corriger les 404 externes ?
Observez la liste obtenue page par page et il ne vous reste plus qu’à faire des redirections 301 vers les pages adéquates.
Si vous n’avez pas de pages correspondantes, renvoyez en 301 sur la homepage ou la page avec le plus d’enjeu SEO pour vous.
La soft 404
Différente des 404 classiques, qui ne renvoie pas de code d’erreur mais un code 200.

Cela se produit quand la page n’existe pas ou ne comporte pas de contenu principal. Pour le budget crawl, c’est une perte sèche de parcourir ces pages inutiles.
Identifier les soft 404

Une fois sur cette page, exportez les soft 404.
Catégorisez les pages selon leur problème (pages vides, contenus trop courts, redirections incorrectes…) puis corrigez-les par batch.
Comment corriger les soft 404 ?
Pour les pages inexistantes :
- Configurer un véritable code 404
- Mettre en place une page 404 personnalisée avec des suggestions de contenu
Pour les pages avec peu de contenu :
- Enrichir le contenu s’il est pertinent de garder la page
- Rediriger vers une page plus pertinente avec une 301
- Supprimer la page avec un 410 si obsolète
Pour les pages de recherche sans résultats :
- Implémenter la balise meta robots « noindex »
- Ajouter du contenu alternatif ou des suggestions
- Rediriger vers la page de recherche principale
Pour les produits indisponibles :
- Conserver la page avec un message clair + suggestions de produits similaires
- Ou rediriger vers la catégorie parente avec une 301
Erreur n°2 : trop de liens internes
Un maillage inefficace vient aussi de la mise en place de liens qui n’ont pas de cohérence globale.
Résultat : dilution du PageRank interne au détriment des pages stratégiques.
Une surabondance de liens a plusieurs impacts :
1 – Un problème pour le SEO
Avec trop de liens, chaque lien transfère une fraction minime du PageRank et le suivi de la diffusion devient de plus en plus difficile pour un SEO à mesure que le site grandit.
2 – Un problème pour le moteur
L’autre problème est que l’abondance de liens va générer du bruit pour Google.
L’algorithme doit en analyser davantage, ce qui peut compliquer l’interprétation des signaux et la découverte des pages importantes. En bref, la densité excessive de liens rend l’architecture plus confuse.
Ce n’est pas forcément dramatique mais chaque couche de complexité supplémentaire augmente les chances d’incompréhension et les ressources nécessaires au moteur pour capturer l’information.
WebRankInfo a d’ailleurs partagé dans un de ses articles le nombre maximum de liens internes préconisé. Je rejoins son opinion donc je vous remets le tableau ici :
| À quel endroit ? | Nb max de liens | Explications |
|---|---|---|
| dans le contenu principal | environ 2 à 5 pour 1000 mots | liens utiles et contextualisés uniquement, espacés |
| dans un listing | environ 50 | pour réduire la nécessité de la pagination |
| dans le menu | quelques dizaines | au-delà on a les problèmes d'un méga menu |
| dans toute la page | environ 150 à 200 | il y a des exceptions pour les gros sites |
À ce sujet, c’est le moment de vous parler de la distinction entre les liens de navigation et les liens contextuels.
- Les liens de navigation sont dans le menu, le footer, ou dans les barres latérales. C’est souvent des mega-menus que viennent les soucis de dilution du PRi.
- Les liens contextuels sont dans la zone principale de la page.
Et comme une image vaut mieux que mille mots, voici un schéma sur la puissance des liens internes sur une page dans le contexte du surfeur raisonnable.

En bref, environ 70% du poids des liens repose sur la partie unique de la page et les 30% restants sont divisés entre les différents boilerplates.
Moment définition : boilerplate
Le boilerplate représente les éléments répétitifs d’un site web (header, footer, menus de navigation, sidebars…) qui se retrouvent sur toutes les pages d’une section du site.
Pour un crawler comme Google, un lien situé dans le contenu principal (hors boilerplate) a plus de poids car :
- Il est placé intentionnellement dans un contexte éditorial spécifique
- Il reflète une relation potentiellement plus forte entre 2 urls
- Il est généralement plus pertinent pour les utilisateurs car il enrichit directement le contenu
Comment savoir si mon site A trop de liens internes ?
L’une des techniques les plus simples est de se rendre dans Screaming Frog et d’observer les pages contenant le plus de liens sortants.
Si une page sort du lot, tentez de comprendre pourquoi : Est-ce une erreur technique ? Est-ce lié à un menu ? À des commentaires ?
Honnêtement, les causes peuvent être très variées, mais voici celles que l’on rencontre le plus :
- menus trop volumineux
- liens automatiques excessifs
- footers surchargés
- tags/catégories mal gérés
- liens contextuels dans le contenu
- paginations excessives

J’en profite pour vous glisser une petite astuce pour savoir si la navigation peut poser problème.
- Sur Screaming Frog, cliquez sur la page d’accueil.
- RDV dans l’onglet du bas sur les liens sortants
- Sélectionner les hyperliens et triez par Navigation
- En bas à droite s’affiche le nombre de liens dans la Navigation. Vérifiez que celui-ci semble normal

Note : Screaming Frog n’est pas infaillible sur la position des liens. Vous pouvez aussi filtrer par « [Position du lien] Not Contains ‘Contenu' » et vérifier le nombre de liens non contextuels.
Et si vous identifiez un surplus de liens ? Place à la correction.
Comment corriger une surabondance de liens internes ?
Malheureusement, il n’existe pas de réponse toute faite sur cette question et chaque cas demande une stratégie adaptée.
Pour les menus trop volumineux (mega-menus) :
- Restructurer en sous-catégories logiques
- Obfusquer les liens vers les pages non stratégiques
- Implémenter un menu à plusieurs niveaux avec les sous niveaux chargés en JS
- Limiter l’affichage aux catégories principales
- Supprimer les catégories redondantes ou peu utilisées
Pour les liens automatiques excessifs :
- Revoir les règles de génération automatique (plus ou moins complexe suivant le CMS…)
- Limiter le nombre de produits/articles similaires affichés (6-9 est une bonne base)
- Mettre en place un seuil maximum de liens automatiques
- Filtrer selon la pertinence thématique (par exemple pour les articles similaires)
Pour les footers surchargés :
C’est un souci moins courant qu’on ne le pense, mais voici quelques pistes :
- Nettoyer les liens obsolètes ou peu utilisés
- Regrouper les liens par sections logiques
- Conserver uniquement les pages essentielles et obfusquer ou supprimer les autres
- Éviter la duplication avec le menu principal
Pour les tags/catégories mal gérés :
- Fusionner les tags/catégories similaires
- Ne pas utiliser ces pages automatiques
- Implémenter une hiérarchie plus claire
- Limiter le nombre de tags par contenu (1 ou 2)
- Supprimer les tags peu utilisés (min 5 contenus par tag sinon on fusionne)
Pour les liens contextuels dans le contenu :
- Garder uniquement les liens réellement pertinents
- Espacer les liens (éviter les paragraphes sur-optimisés)
- Privilégier la qualité à la quantité (pour un contenu blog 6-15 liens est une bonne base)
- Vérifier le glissement sémantique et supprimer les liens non pertinents (sauf s’ils ont un rôle dans la conversion)
- Supprimer les liens redondants
Pour les paginations excessives :
On revient un peu plus loin sur cet aspect, voici deux pistes pour le moment :
- Augmenter le nombre d’items par page (aucun souci à en afficher 50)
- Optimiser l’architecture des catégories et mettre en place des filtres plus précis pour ne pas avoir trop de produits dans une catégorie donnée
Erreur n°3 : trop peu de variété d’ancres
Un manque de variété dans les ancres de liens internes peut poser plusieurs problèmes, notamment une limitation du positionnement sur des mots-clés secondaires.
En utilisant systématiquement la même ancre pour les liens pointant vers une page donnée, on restreint la capacité de cette page à se positionner sur une variété de mots-clés pertinents. Diversifier les ancres permet de cibler un éventail plus large de requêtes, augmentant ainsi le trafic organique.
On considère souvent qu’après 30 liens sur la même ancre, rajouter encore et encore des liens sur cette même ancre n’aidera pas à son positionnement.
![]() Lorsqu’une page A contient plusieurs liens pointant vers une même page B, seul le premier lien apparaissant dans le code source de la page A sera pris en compte pour l’ancrage (ou l’ancre textuelle).
Lorsqu’une page A contient plusieurs liens pointant vers une même page B, seul le premier lien apparaissant dans le code source de la page A sera pris en compte pour l’ancrage (ou l’ancre textuelle).
Regardez l’exemple juste après car c’est important !
Si 12 pages différentes font un lien vers la page B, les 12 liens sont pris en compte.
Mais si sur une même page, tu fais deux liens vers B — un en haut (“services marketing”) et un en bas (“agence SEO”) — seule la première ancre rencontrée (“services marketing”) sera interprétée par Google.
Ainsi, si le premier lien de chacune des 12 pages utilise la même ancre textuelle (par exemple « services marketing »), alors seule cette ancre sera comptabilisée pour l’analyse, même si d’autres liens avec des ancres différentes existent plus bas dans le code source de ces pages.
Identifier les manques de variété d’ancres
Pour analyser vos manques d’ancres vers les pages stratégiques, je vous recommande de passer par l’outil d’analyse des ancres internes de Thot. C’est 100% gratuit et il vous donnera précisément toutes les pages problématiques.

Pour utiliser l’outil, il faut d’abord passer par un audit Screaming Frog. Par simplification, nous allons rester sur l’exemple de Protéalpes.
Une fois l’audit terminé, exportez les liens entrants du site. Pour ce faire, on se rend dans “Exportation en bloc” → “Liens” → “Liens entrants tous” → export en CSV.

Ensuite, on retourne sur l’interface de l’outil, et on charge notre fichier CSV.

Une fois le fichier CSV chargé, l’analyse prend entre 5 secondes et 5 minutes et vous verrez s’afficher les premières données et notamment les URLs avec trop peu d’ancres différentes.

Décrivons rapidement la première ligne qui permet d’avoir un aperçu du site. Sur ces résultats, nous pouvons identifier plusieurs choses :
- Il y a tout d’abord les liens internes dans le fichier (c’est-à-dire tous les liens du site).
- Les liens retenus qui transmettent du PageRank entre elles. Pour l’analyse, on exclut les liens 404, les fichiers JavaScript ainsi que les images.
- L’outil fournit enfin les URLs indexables distinctes analysées, et le nombre de mots moyen par ancre.
Vous pouvez ensuite découvrir le nombre d’URLs qui ont trop peu de liens internes. Dans notre exemple, 141 pages sont concernées. C’est-à-dire que 141 pages ont moins de 7 liens qui pointent vers elles.
Enfin vient ce qui nous intéresse : la variété d’ancres.
ThotSEO propose deux “versions” : trop peu de variétés d’ancres en comptant tous les liens d’une page, et trop peu de variété d’ancres en comptant uniquement le premier lien de chaque page. Le second indicateur étant, à priori, le plus important des deux.
La cannibalisation par les ancres, quant à elle, représente les ancres qui sont identiques pour plusieurs pages mais nous y reviendrons un peu plus loin.
Juste en dessous, nous avons des graphiques pour illustrer les audits. N’hésitez pas à abuser des screenshots au besoin, c’est gratuit.

Sur le site de Protéalpes, on remarque qu’environ 60% des liens n’ont pas suffisamment d’ancres différentes.
Sur le graphique en barre, nous remarquons notamment une forte concentration d’URL avec seulement 1 ancre, représentant près de 33 % des urls.
Le second graphique en barre donne des indications sur la répartition du nombre de liens uniques par page.
Certaines pages dépassent largement les 11 ancres uniques, ce qui indique une structure bien connectée pour une minorité d’entre elles.
L’étape suivante est l’analyse du détail des ancres, disponible un peu plus bas dans la page. Vous pouvez trier par nombre d’ancres distinctes pour identifier les problèmes les plus urgents.
Notez que les ancres dans « Liste de ancres » ne sont QUE les premières dans le code source.

Si vous avez de nombreuses pages touchées (c’est probable) je vous conseille de trier les pages en fonction de leur potentiel de conversion et de démarrer par là.

Comment améliorer ma diversité d'ancres de liens ?
La première étape est de prioriser. Je vous conseille de commencer avec une dizaine de pages à reprendre et d’aller observer les ancres actuelles.
Ici par exemple, on est sur un cas typique de e-commerce qui ne donne aucune chance à certains produits !

Il nous faut à présent nous rendre sur des pages du site pour aller intégrer des liens contextualisés sur des ancres sélectionnées avec soin.
La méthodologie exacte est donnée avec moulte détails et exemples dans la section « Optimisation d’une page existante » !
En très bref, nous allons lancer une analyse ThotSEO sur la requête cible de la page (ici mass gainer vanille) et nous rendre dans l’onglet maillage interne pour avoir une liste d’URL pertinentes DEPUIS lesquelles faire des liens. Ces URLs sont sélectionnées pour leur glissement sémantique avec le sujet.

Pour le choix des ancres, une simple consultation de la GSC nous donnera plusieurs idées. Encore une fois, c’est ici un très bref résumé mais la méthodologie entière est détaillée un peu plus bas.

Erreur n°4 : les liens NoFollow
Les liens en NoFollow restent à éviter pour éviter de perdre du PageRank.
En termes de conservation du PRi, un lien en NoFollow est bien pire que de faire un lien externe.
Pourquoi ? Le lien externe vers une page proche de votre thématique va garder le surfeur dans une zone d’internet proche de vos pages, ce qui augmente la probabilité qu’il se retrouve sur votre site sous peu.
Un lien NoFollow, quant à lui, envoie le surfeur dans l’immensité de l’index Google, et les chances qu’il retourne rapidement sur vos pages sont minimes.
Pour ne pas perdre le jus, privilégiez les liens qui n’ont pas d’attributs Nofollow, voire des liens obfusqués. Les liens obfusqués permettent de canaliser le PageRank vers les pages souhaitées (on y reviendra).

Pire encore qu’un lien NoFollow, en plus d’appliquer individuellement l’attribut nofollow à chaque lien, il est possible de mettre en nofollow tous les liens d’une page en utilisant la balise meta robots :
<meta name= »robots » content= »nofollow »>
Cela signifie qu’aucun lien sortant de la page, qu’il soit interne ou externe, ne transmettra de PageRank.
Cette directive meta nofollow globale est une solution plus destructrice encore car elle impacte sans distinction tous les liens de la page.
Identifier les liens NoFollow
Pour la balise meta robots <meta name= »robots » content= »nofollow »> vous pouvez trouver directement les pages impactées sur Screaming Frog.
Rdv dans Directives puis filtrez par Nofollow

Pour les liens en NF, il vous suffit d’aller dans la section Liens sur la droite et de sélectionner les liens sortants Nofollow internes.

Mais cela ne concerne que les liens internes. Les liens en NF vers d’autres sites sont aussi un problème (nous avons vu plus haut pourquoi).
Pour les trouver, voici ma première méthode :

Concernant la correction c’est très simple :
Si vous identifiez des liens NF en internes : retirez le nofollow. Jamais de NF en interne, point.
Si vous identifiez des liens NF vers l’extérieur : retirez le nofollow SAUF si c’est dans les commentaires des articles ou autre espace où les utilisateurs peuvent eux-même placer des liens. Dans ce cas, le mieux reste de les obfusquer mais cela est un peu plus technique.
Erreur n°5 : les ancres cannibales
On parle d’ancre cannibale dès que plusieurs pages d’un site reçoivent un lien sur la même ancre de lien (souvent un mot-clé principal).
Dans ce cas de figure, le moteur de recherche a plus de mal à déterminer la page la plus pertinente pour ce mot-clé.
Chaque lien interne est l’occasion de donner une indication claire sur ce que traite la page par rapport aux autres et ce qu’elle ne traite pas.
Notez que le seul cas où plusieurs pages peuvent avoir des ancres optimisées similaire est dans l’objectif de multi-ranking. On cherche à positionner deux pages de formats distincts, visant des intentions différentes, sur une même SERP. Par exemple, pousser un article éditorial et une landing pour attaquer une SERP mixte.

![]() Une grande part des problèmes de cannibalisation viennent de là. Quand ce n’est pas la bonne page qui rank sur une requête donnée, une repasse complète sur la maillage interne permet souvent de le résoudre.
Une grande part des problèmes de cannibalisation viennent de là. Quand ce n’est pas la bonne page qui rank sur une requête donnée, une repasse complète sur la maillage interne permet souvent de le résoudre.
Identifier les ancres cannibales
Pour creuser vos ancres dans le détail, de nouveau je vous conseille d’utiliser l’outil d’analyse des ancres internes de Thot. Il vous donnera précisément toutes les ancres cannibales sur le site et vous gagnerez un temps précieux sur l’audit et la correction.
Pour la première phase de récupération des données nécessaires à l’analyse, je vous renvoie à la section « Trop peu de variété d’ancres » un peu plus haut.
Une fois le fichier CSV chargé, on obtient les résultats de l’analyse et notamment le nombre d’ancres cannibales.

L’étape suivante est l’analyse du détail des ancres, disponible un peu plus bas dans la page.
À partir de là, il y a deux options :
- Analyser une URL spécifique (si vous soupçonnez une cannibalisation par exemple)
- Auditer les ancres cannibales globalement
Pour analyser une URL spécifique, il vous suffit de la sélectionner dans la première liste et de vérifier s’il y ou non des problèmes potentiels.

Vous pouvez aussi consulter le détail des ancres cannibales avec leur SOURCE et leur DESTINATION.

Pour auditer et corriger les ancres à l’échelle du site (ou des pages crawlées du moins), descendez un peu plus bas pour sélectionnez les ancres que vous souhaitez exporter.

N’incluez que les ancres vraiment problématiques. Les ancres génériques sont normales et à ignorer. Une fois la liste faite, recliquez sur le bouton pour l’exporter en CSV. Vous aurez le détail pour chacune des sources et des destinations.

Comment corriger les ancres cannibales ?
Le processus de correction est en 2 étapes : décision et action.
1 – Décision
- Déterminer la page cible prioritaire : parmi les pages qui se disputent la même ancre, identifiez la plus pertinente pour la requête visée.
- Évaluer la pertinence du multi-ranking : si vous souhaitez positionner deux formats différents (ex. un article et une landing page) sur la même SERP, conservez deux ancres optimisées. Sinon, une seule page doit être conservée comme cible principale.
Une méthode un peu longue mais efficace est de descendre le tableau et de décider à chaque fois s’il faut conserver l’ancre (car la page de destination est la bonne) ou la modifier.

2 – Action
Une fois la décision prise, pour toutes les ancres à modifier RDV sur chaque page source et changez l’ancre vers la page de destination. Pour le choix des ancres, je vous renvoie à la section « optimisation d’une page existante » de ce guide (ThotSEO et la GSC seront vos alliés).
L’objectif de l’opération est de lever toute ambiguïté concernant l’intention de recherche traitée par une page. Pensez à faire un second crawl par la suite pour vérifier que tout a bien été corrigé et que cela n’a pas induit de nouveaux soucis.
Erreur n°5 : profondeur d’exploration excessive
D’après l’étude d’Olivier Duffez pour la plateforme My Ranking Metrics, qui a calculé la profondeur de 24 millions de pages provenant de plus de 8000 sites, il s’est avéré que les pages de profondeur 1 à 3 génèrent 9 fois plus de visites en SEO que les pages plus profondes.
Nombre moyen de visites générées via Google sur 30 jours par page (clics Search Console) selon la profondeur de la page :
Hormis ce calcul, il y a une logique implacable : les pages profondes ont du mal à recevoir du PageRank, ce qui fait fait baisser leurs performances SEO.
En termes de profondeur maximale, il n’y a pas de règle universelle. Comme tout en SEO, “ça dépend”. Les sites ont différentes tailles : quelques dizaines de pages contre quelques millions implique des priorisations différentes.
Identifier les pages profondes
Pour l’identification des pages profondes, vous pouvez utiliser Screaming Frog. Avant de lancer votre analyse, il faut la configurer en allant dans « Configuration > Spider > Limites ».

Laissez l’option “Limiter la valeur crawl profondeur” décochée.

Une fois l’analyse terminée, rendez-vous dans « Internes » et localisez la colonne « Crawl profondeur ».
Gardez en tête que les redirections comptent comme une 1 profondeur supplémentaire.

Dans la colonne « Liens », vous trouverez un filtre appelé « Pages avec un crawl profondeur élevé ». Mais attention ! Pour activer cette option, vous devez tout d’abord lancer une analyse de crawls en allant dans « Configuration > Analyse du crawl » et vérifier que « Liens » est coché avant de lancer l’analyse.
Une fois que c’est fait, vous avez maintenant accès au filtre « Pages avec un crawl profondeur élevé ».

Pour plus de visibilité sur les filtres, vous pouvez exporter cette liste vers Excel ou Google Sheets.
Vous pouvez aller plus loin en priorisant les actions sur ces pages profondes, grâce à la connexion Screaming Frog – Search Console.
Assurez-vous d’abord d’avoir une connexion à la GSC.

Lancez le crawl, et inspectez la colonne « Impressions ».

Vous pouvez filtrer la profondeur de crawl et les impressions pour arriver à prioriser vos actions correctives.

Comment réduire la profondeur de vos pages ?
Il faut bien distinguer les actions rapides pour remonter quelques pages stratégiques VS la corrections globale d’un souci de profondeur.
Dans les actions à impact rapide on a :
- Remonter les pages stratégiques via des liens directs depuis la home/menu
- Corriger les problèmes techniques bloquants (redirections en cascade, canoniques)
- Optimiser le fil d’Ariane vers les pages clés
- Simplifier la structure des catégories trop profondes
Et pour les optimisations progressives :
- Améliorer le maillage interne général
- Créer des pages d’index thématiques
- Affiner la structure globale du site
- Surveiller l’évolution via des crawls réguliers
- Simplifier votre structure de liens internes en hiérarchisant ces liens. Pour ce faire, relier stratégiquement les pages pertinentes pour créer une hiérarchie logique.
- Limiter les filtres de navigation accessibles aux crawlers. Dans l’idéal, faites en sorte d’avoir un ou deux filtres maximum, pour éviter les combinaisons inutiles qui créeront des pages profondes qui n’auront jamais de trafic organique.
Il existe d’autres conseils plus généraux comme une pagination limitée, une réduction du nombre de pages, et en dernier recours un plan de site HTML pour rendre vos pages profondes accessibles plus facilement.
Attention à ne pas faire plus de mal que de bien. La profondeur est aussi un signal pour l’importance d’une page. Une solution artificielle avec 100% des pages accessibles depuis la home serait contre-productif, car un moteur aurait alors plus de mal à déterminer les pages prioritaires.
Erreur n°6 : navigation à facettes mal gérée
La navigation à facettes, souvent utilisée en e-commerce, est une approche UX qui permet de filtrer les résultats de recherche internes grâce à plusieurs critères.
Mais pour mettre en place une navigation SEO-friendly, il y a quelques règles à respecter.
Prenons un exemple pour bien comprendre le concept, puis nous passerons à un exercice concret et ULTRA pratique.
Exemple et illustration des facettes
Imaginons un site e-commerce de vêtements avec des filtres mal configurés :
Sur ce site, on trouve la catégorie « Robes » avec ces options :
- Taille (6 options) : XS, S, M, L, XL, XXL
- Couleur (8 options) : Noir, Blanc, Rouge, Bleu, Vert, Rose, Jaune, Violet
- Prix (4 ranges) : 0-50€, 50-100€, 100-200€, 200€+
- Style (5 options) : Casual, Soirée, Business, Bohème, Sport
- Matière (6 options) : Coton, Lin, Soie, Polyester, Laine, Jean
Calcul de l’explosion : 6 (tailles) × 8 (couleurs) × 4 (prix) × 5 (styles) × 6 (matières) = 5,760 URLs possibles
Exemples d’URLs générées :
/robes?taille=M&couleur=noir&prix=50-100&style=soiree&matiere=soie
/robes?taille=L&couleur=rouge&prix=0-50&style=casual&matiere=coton
/robes?taille=S&couleur=bleu&prix=200plus&style=business&matiere=laine
Cela pose PLEIN de problèmes :
- Dilution du PageRank entre 5760 URLs juste sur cette catégorie alors que les utilisateurs cherchent sans doute moins de 1 ou 2% des combinaisons
- Budget crawl gaspillé (imaginez cela avec 20 catégories de vêtements)
- Contenus dupliqués (mêmes produits, ordre différent)
- Pages avec 0 résultat indexé car l’immense majorité des filtres ne donnent sans doute aucun résultat
Avant de passer à l’identification des problèmes et à leur correction, il est intéressant de passer par une petite mise en pratique.
Pour cet exemple, prenons un exercice concret.
Imaginez un site de jeu vidéos où un utilisateur peut trouver une manette de jeu rouge en commençant via une catégorie manette, via une marque ou un modèle de console ou juste par l’accessoire ou la couleur.
https://example.com/gaming/manette/playstation-4/rouge
https://example.com/gaming/sony/manette/rouge
https://example.com/gaming/manette/rouge
https://example.com/gaming/rouge/manette
…

Mais laquelle ou lesquelles indexer ? Voici mon petit protocole, je vous conseille de l’adapter à votre pratique et votre cas précis.
1 – Analyse préalable
Étudier les données Analytics pour identifier les chemins navigationnels les plus utilisés :
Analyser le volume de recherche pour chaque variante (« manette PS4 rouge » vs « manette rouge sony » etc.)
Ensuite, on va identifier le chemin de réflexion : on cherche d’abord un accessoire rouge pour sa PS4 VS on a besoin d’une manette puis on décide d’une couleur ? Probablement la seconde option :
- Besoin initial : « Je veux une manette PS4 »
- Critère secondaire : « Je la voudrais en rouge »
- Comparaison : Prix, délais, avis
Enfin, on va vérifier les intentions de recherche dominantes qui ressortent de la SERP sur les différentes requêtes. Quels sont les produits présentés ? Comment se sont structurés nos concurrents ?
Exemple :
- Les résultats montrent principalement des pages catégories de manettes PS4 avec filtre rouge
- Images Shopping dominantes en haut de page
- « Autres couleurs disponibles » souvent mentionné dans les descriptions
- Analyse des Position 1-3 ou 4 : Amazon, Fnac, Cdiscount avec URLs type « /manette-ps4/rouge
-
- Amazon : /playstation-4/manettes/rouge
- Fnac : /gaming/ps4/manette?couleur=rouge
- Cdiscount : /manette-ps4-rouge.html
- Micromania : /accessoires-ps4/manettes/couleur-rouge
Cette analyse nous montre clairement que :
- Les utilisateurs pensent d’abord « manette PS4 » puis « couleur »
- Le volume de recherche confirme cette hiérarchie
- Les concurrents performants suivent cette logique
→ Décision : Nous allons centraliser sur /gaming/manette/playstation-4/rouge
Vient maintenant la mise en pratique ! Comment intégrer cela dans notre technique de site ?
2 – Implémentation technique
On commence par le robots.txt
User-agent: *
# Autoriser les pages principales
Allow: /gaming/manette/playstation-4/
Allow: /gaming/manette/
Allow: /gaming/
# Bloquer les chemins alternatifs spécifiques
Disallow: /gaming/sony/manette/rouge
Disallow: /gaming/rouge/manette
Disallow: /gaming/manette/rouge
# Bloquer les paramètres
Disallow: /*?color=
Disallow: /*?brand=
Disallow: /*?sort=
On va également inclure certaines balises sur nos pages HTML
<!– Sur la page canonique /gaming/manette/playstation-4/rouge –>
<link rel= »canonical » href= »https://example.com/gaming/manette/playstation-4/rouge » />
<!– Sur les pages alternatives –>
<link rel= »canonical » href= »https://example.com/gaming/manette/playstation-4/rouge » />
<meta name= »robots » content= »noindex,follow » />
Et on termine par les redirections adéquates dans le fichier .htaccess
RedirectMatch 301 ^/gaming/sony/manette/rouge$ /gaming/manette/playstation-4/rouge
RedirectMatch 301 ^/gaming/rouge/manette$ /gaming/manette/playstation-4/rouge
RedirectMatch 301 ^/gaming/manette/rouge$ /gaming/manette/playstation-4/rouge
Notez que l’on ne bloque pas les pages catégories principales (ex : /gaming/manette/playstation-4/) et que l’on va rediriger les variantes vers l’URL canonique.
Niveau UX, cela ne change rien. On va laisser les filtres accessibles aux utilisateurs, mais les rendre non indexables.
Avec cet exercice, vous comprenez que le problème des facettes mal configurées réside donc dans les URLs générées.
Pour votre culture, il existe plusieurs méthodes de génération suivant les CMS :
- Créer des sous-répertoires : une nouvelle URL statique est créée pour chaque facette appliquée, par exemple
vetements/chemises/funko/. - Intégrer des paramètres dans l’URL, par exemple
?color=red&brand=sony. - Utiliser une méthode dynamique en AJAX mais sans que l’URL ne reflète les filtres sélectionnés.
- Employer des fragments d’URL (hachages) pour indiquer les facettes appliquées, par exemple
#color=red.
Au final, peu importe la méthode d’organisation de l’URL, le souci est l’indexabilité de ces pages générées.
Comme nous l’avons vu, il ne faut pas TOUTES les indexer, mais dans le même temps, n’en indexer aucune serait se priver d’un important trafic de longue traîne.
Pour vous aider je vous ai préparé un petit arbre décisionnel :
Faut-il indexer ma page facette ?
Y a-t-il une demande de recherche suffisante pour que cette page existe ?
Ai-je l'inventaire nécessaire pour supporter cette page ?
Passons maintenant à la partie de détection du problème.
Identifier les explosions de facettes
Pour identifier les facettes, nous pouvons commencer par une simple recherche du site sur Google via l’opérateur site:domaine
Allez ensuite dans « Outils » pour voir le nombre de pages et une éventuelle surcharge de l’index.

Pour identifier les facettes, nous pouvons passer par la Search Console.
Allez sur le rapport « Pages » et vous pourrez déjà observer ou non une explosion des pages.

Filtrez ensuite sur les URL qui contiennent vos paramètres de facettes (?sort=, ?filter=, ?page=)

Vous pouvez également analyser l’impact des pages à facettes sur le budget de crawl, en allant dans « Paramètres > Statistiques d’exploration ».
C’est assez basique, mais avec l’export et armé d’un Google Sheet, vous pouvez vérifier la part du crawl dédiée à des URLs à facettes. Le mieux reste une analyse des logs, mais c’est un peu plus technique.

Si vous obtenez des URL à facettes indexées mais qui ne devraient pas l’être, quelques conseils ci-dessous ⬇️
Comment mieux gérer les facettes ?
Faites tout d’abord une analyse des volumes de recherche pour chaque facette. Si certaines ont un très faible volume, vous n’avez pas besoin qu’elles soient explorées et indexées.
Vous pouvez alors les bloquer :
- En interdisant l’exploration de ces pages dans le robots.txt. Cependant, elles peuvent toujours être explorées et indexées si elles sont maillées au reste du site.
- Utilisez les canonicals sur les catégories principales et faire en sorte que les pages à facettes pointent vers leurs pages parentes.
- Utilisez noindex pour bloquer l’indexation. Pratique sur le papier, mais cela n’empêche pas l’exploration des pages, ce qui ne résout pas le problème du budget d’exploration gaspillé.
- Une solution plus optimale serait de passer par AJAX : une nouvelle liste sera générée sans rechargement de pages, ce qui enlève la gestion des URLs à facettes.
- Vous pouvez aussi limiter les combinaisons de filtres possibles sur l’interface (ex : max 2 critères)
Erreur n°7 : l’abus de pagination
Dans l’idéal, évitez la pagination sur votre site.
- Pour l’utilisateur, c’est une gêne car il doit attendre le chargement d’une nouvelle page
- Pour le moteur, c’est du budget crawl gâché à cause de la multiplication des URL
- C’est aussi une dilution du PRi, notamment à cause de la multiplication des URLs
La pagination peut être source de NOMBREUSES erreurs. Il faudrait un dossier entier pour toutes les traiter.
Une bonne partie des erreurs est le pendant des bonnes pratiques données plus loin. Parmi les plus courantes :
- Une page qui comporte plusieurs attributs rel= »next » et rel= »prev » (il ne devrait y en avoir qu’un seul).
- Les URL contenues dans les attributs rel= »next » et rel= »prev » de la page, ou dans les deux, ne sont pas trouvées en tant qu’hyperlien <a> sur la page elle-même.
Les pages paginées doivent être reliées par des liens ordinaires pour permettre aux utilisateurs de cliquer et de naviguer jusqu’à la page suivante de la série.
-
Les URL contenues dans les attributs rel= »next » et rel= »prev » ne répondent pas avec un code d’état 200. Il peut s’agir d’URL bloquées par robots.txt, pas de réponses, 3XX (redirections), 4XX (erreurs du client) ou 5XX (erreurs du serveur).
- Une erreur de séquence. Chaque page paginée doit pointer correctement vers la suivante (
rel="next") et, si applicable, vers la précédente (rel="prev"). Il y a un problème si l’un des liens pointe vers une URL qui ne le reconnaît pas en retour, ou si la séquence est brisée (par exemple, une page 2 qui ne pointe pas correctement vers la 3, ou une page finale qui continue à pointer vers une suivante inexistante). -
Les URL contenues dans les attributs rel= »next » et rel= »next » ne sont pas maillées avec le reste du site. Les attributs de pagination ne transmettent pas le PageRank comme un <a> traditionnel.
-
Les URL qui ont des attributs rel= »prev » et rel= »next » qui renvoient en boucle à une URL rencontrée précédemment.
-
L’URL paginée n’est pas indexable. En général, elles devraient toutes être indexables, à moins qu’une page « view-all » ne soit définie ou qu’il y ait des paramètres supplémentaires sur les URL de pagination, et qu’elles nécessitent une canonisation vers une URL unique.
-
Canoniser les pages paginées > à 1 vers la première page. Google déconseille cette pratique, car les pages qui la composent ne contiennent pas réellement de contenu dupliqué.
-
Enfin, une autre erreur courante consiste à utiliser la fonction « noindex » sur les pages paginées.
Identifier les problèmes de pagination
Pour identifier les problèmes de pagination sur votre site, vous devrez obligatoirement effectuer un crawl complet. Certaines erreurs comme les boucles ou les séquences ne peuvent pas être analysées manuellement via une extension ou une inspection du code source (ce qui prendrait un temps fou).
Pour le crawl, je vous recommande Screaming Frog ou RM Tech.
Pour un audit rapide à l’échelle d’une page (pour observer les erreurs de canonicals par exemple), vous pouvez :
- utiliser la Search Console (pas très pratique)
- utiliser un plugin chrome (Ahrefs, Detailed SEO…)
- ouvrir et fouiller dans Chrome DevTools (un peu barbare mais efficace)
L’objectif de la manœuvre est de vérifier que les balises rel= »prev » et rel= »next » sont bien présentes sur vos pages paginées et que les canonicals ne desservent pas les pages.
Pour vérifier cela, rendez-vous sur une page 2 de votre site, par exemple sur le blog.

Ici, nous avons une indication pour Google : la page 1 est canonique. C’est une mauvaise pratique, car le moteur risque de ne pas considérer vos pages 2, 3 et suivantes.

Via un plugin on peut détecter le même problème :

Moins direct, vous pouvez également passer par la Search Console.
Option 1 : aller dans le rapport « Pages » dans l’onglet Indexation. Filtrez pour voir si des pages paginées sont classées comme « Explorée, actuellement non indexée » (Google crawle mais ne les indexe pas) ou dans « crawlée, non indexée » (problème possible avec un noindex ou une canonical).

Option 2 : plus direct, vous pouvez prendre l’une des pages de pagination et aller dans l’inspecteur d’URL.

Mais encore une fois, rien ne vaut un crawl complet. Après l’analyse de Screaming Frog, trouvez cet onglet et vous aurez déjà une bonne base.
Mais notez qu’il n’est pas exhaustif et qu’il vaut mieux vérifier les autres éléments manuellement ou prendre des crédits RM Tech si vous soupçonnez des problèmes importants.

Comment corriger les problèmes de pagination ?
Pour corriger vos problèmes de pagination, plusieurs possibilités :
- Ne pas placer de balise canonical pour la page 1, car cela risque de ne pas partager l’autorité aux pages 2 et suivantes pénalisant ainsi le ranking des produits présentés.
La balise rel= »canonical » est utilisée pour indiquer à Google quelle est la version principale d’un contenu lorsque plusieurs URL présentent des contenus très similaires. Or, les pages de pagination ne sont pas identiques à la page 1 : elles listent des éléments différents.
- Évitez également les balises noindex sur les pages paginées.
- Pour optimiser votre budget de crawl, bloquez les pages trop profondes (50 et + par exemple) dans robots.txt : Disallow: /*?page=50$
- Si vous voulez vraiment opter pour un scroll infini, assurez-vous d’avoir un lien HTML qui rend accessible les pages suivantes : une version « progressive enhancement » du scroll infini (affichage AJAX + liens HTML en fallback).
Globalement, le mieux reste de mettre en place des catégories et sous-catégories pour éviter d’avoir une pagination.
Mais si vous avez quand même besoin d’une pagination, voici une liste de bonnes pratiques données par Olivier Duffez dans son guide dédié :
- Autoriser le crawl des pages paginées via le fichier
robots.txt. - S’assurer d’avoir un code HTTP 200 pour toutes les pages.
- Fournir des liens cliquables et follow vers les pages
nextetprev. - Utiliser des balises
<link rel="next">et<link rel="prev">dans l’en-tête HTML pour indiquer la séquence. - Ajouter du contenu éditorial unique et pertinent sur la page 1 et ne pas le répliquer sur les suivantes.
- La page 1 doit toujours avoir une URL cohérente (pas de variations comme
/page=1). - Garantir que les balises
next/prevrespectent une séquence cohérente et ne créent pas de boucle infinie. - Éviter d’utiliser les attributs
rel=next/prevdans les balises<a>. - Afficher le texte de présentation uniquement sur la page 1.
- Augmenter le nombre d’éléments par page pour réduire le besoin de pagination. C’est le cas par exemple pour la page catégorie d’un site e-commerce : le nombre de produits présents semble jouer un rôle important sur de nombreuses requêtes. Dans l’idéal, il vaut mieux maximiser le nombre de produits sur sa page catégorie (sans en abuser).
- Ne pas inclure la pagination sur des pages non listées (exemple : articles d’un blog).
Erreur n°8 : les chaînes et boucles de redirection
Une chaîne de redirection se produit quand plusieurs redirections sont mises en place entre une URL initiale et sa destination finale :
- À l’origine, une URL « /anciennes-actualites » est redirigée en 301 vers « /archives » (pour restructurer le blog).
- Plus tard, « /archives » est elle-même déplacée et redirigée en 301 vers « /archives-2020 » (changement pour affiner l’URL).
- Enfin, « /archives-2020 » est rebaptisée « /archives-old » pour une raison SEO et aussi renvoyée en 301 vers la nouvelle URL.
On se retrouve donc avec une chaîne de redirection :

On peut aussi avoir un problème si après quelques mois ou années on décide de changer « /archives-old » en « /anciennes-actualites ». Les 301 vont créer une boucle de redirection infinie et…

Identifier les chaînes et les boucles de redirection
Lancez une analyse sur Screaming Frog, puis Code de réponse en haut à gauche → Filtre vers Redirection 3xx

Ensuite, il faut aller dans Rapports → Redirections → Chaînes de redirection et exporter le fichier.

Une autre approche pour détecter les chaînes de redirection est de passer par le navigateur via Chrome DevTools (Ctrl + Shift + i pour l’ouvrir).

Une fois ouvert, allez dans l’onglet « Network » et cochez « Preserve Log ». Rechargez la page et recherchez « redirects » dans la barre de recherche, ou triez directement la colonne « Status » pour faire apparaître de potentielles chaînes de redirection.

Vous pouvez aussi détecter les chaînes de redirection en utilisant un plugin Chrome comme Link Redirect Trace.

Comment corriger une chaîne de redirection
Une fois ces chaînes identifiées, il faut les corriger :
- Faites une redirection directe vers l’URL finale avec une 301 depuis toutes les pages intermédiaires. Au final, peu importe sur quel lien le crawler arrive, il sera bien redirigé vers l’URL finale directement
- Mettez à jour les liens internes qui pointent vers des URLs redirigées pour n’avoir que l’URL actuelle dans le code source du site
Comment corriger une boucle de redirection
C’est dans les grandes lignes la même chose que pour les chaînes de redirection. S’ajoute à cela :
- Si la boucle provient d’une mauvaise configuration du fichier
.htaccess, il faut la rectifier. Idem pour les sites qui tournent sous Nginx, la boucle peut venir d’une mauvaise règle de réécriture (rewrite). - Si vous êtes sur WordPress, la boucle peut provenir d’un plugin de redirection mal configuré. Dans ce cas, désactivez le et observez si le problème persiste.
- Il peut s’agir d’une mauvaise configuration d’URL dans les réglages WordPress. Vous pouvez vérifier l’URL du site dans « Réglages » > « Général » : il faut que l’URL définie corresponde au bon format (
httpvshttps,wwwvsnon-www). - Videz le cache de votre site, voire de votre serveur.
Erreur n°9 : le wrapper link
Sujet plus technique, c’est quand un lien est placé sur tout un bloc avec différents textes :
Ici par exemple, on a le lien sur l’ancre Pro recovery au cacao Sans gluten, Riche en protéine 34,08€ 800 g 10/10 21 avis garantis
La position de Google là dessus est assez floue. En théorie, il serait capable d’identifier quelle est la partie importante, mais ce ne serait pas la première fois que le moteur annonce quelque chose qu’on ne retrouve pas vraiment dans les tests.
De plus, ce qu’il considère comme important n’est pas forcément ce qu’on VEUT qu’il considère comme majeur.
Et dans les faits, il est indéniable que cela complexifie le traitement de la page et augmente l’information retrieval cost. C’est donc de toute façon soit neutre, soit négatif et à éviter.

L’autre problème courant est l’extrême inverse : on utilise un lien (ici pour rendre tout le bloc cliquable) avec un lien sans ancre.
Ici, même conclusion : peut-être que Google comprend ce qu’on voulait dire, mais probablement pas exactement.
Pour cette page (la home) on a également le lien sur l’ancre “En savoir plus” qui est le premier dans le code source. C’est donc cette ancre qui sera considérée par Google, mais est-ce vraiment mieux ?

Identifier les wrapper links
Pour commencer, et comme pour beaucoup de problèmes de maillage interne, on va se baser sur un crawl Screaming Frog.
Sélectionnez toutes les URLs avec un ctrl+A puis rendez-vous dans liens sortants pour exporter toutes les ancres.

Ensuite, avec votre Google Sheet préféré vous allez ouvrir ce fichier et y ajouter la colonne pour le nombre de mots via la formule :
=SI(ESTVIDE(A2); 0; NBCAR(SUPPRESPACE(A2)) NBCAR(SUBSTITUE(SUPPRESPACE(A2); » « ; « »))+1)
Avec cette colonne, vous allez pouvoir identifier les ancres problématiques en commençant par trier par taille décroissante puis par taille croissante. Vous verrez alors les ancres trop longues et trop courtes clairement liées à une erreur.

Comment corriger un wrapper link ?
Pour corriger les problèmes liés aux wrapper links commencez par cibler précisément le texte d’ancrage.
- Isoler l’élément principal : Plutôt que de mettre un lien sur tout le bloc, placez-le uniquement sur le texte pertinent (titre du produit par exemple)
- Utiliser une ancre optimisée : Choisissez une ancre qui contient le mot-clé principal (ex: « Mass gainer au cacao » au lieu de tout le bloc)
Ensuite, on peut avoir besoin de conserver les blocs entièrement cliquables pour l’UX. Pour cela vous pouvez utiliser CSS avec pseudo-éléments pour rendre la zone cliquable tout en gardant l’ancre optimisée.
<h2><a href=« /product »>Mass gainer au cacao</a></h2>
<p>Sans gluten, Riche en protéine</p>
<p class=« price »>34,08€</p>
</div>
Et le CSS :
position: relative;
}
.product-card::after {
content: « »;
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 1;
}
.product-card a,
.product-card p {
position: relative;
z-index: 2;
}
Vous pouvez également obfusquer le lien en JS. Il existe plusieurs techniques mais la plus simple pour ce genre d’opération reste le span avec
Ou un span avec data-href et un script qui vient récupérer data-href :
Erreur n°10 : les pages orphelines
Vous connaissez sûrement les pages orphelines “classiques” :
- Celles qui n’ont jamais été liées entre elles,
- Les pages supprimées du maillage après une refonte,
- Les pages créées uniquement pour des campagnes pubs.
Les pages orphelines posent problème car ni les utilisateurs ni Google ne peuvent les découvrir facilement via la navigation interne.
Elles risquent donc de ne pas être indexées (ou mal classées) et de ne générer aucune visibilité organique, ce qui peut faire passer à côté d’opportunités de trafic et nuire à la cohérence du maillage interne.
Important : le problème des pages orphelines est un peu plus complexe que cela, car il faut se mettre à la place d’un crawler.
On peut croire qu’une page n’est pas orpheline parce qu’elle reçoit des liens internes, alors qu’en réalité elle l’est aux yeux de Google si ces liens proviennent de pages non indexées (ou non indexables).
")
Puisque ces pages sources n’existent pas du point de vue du moteur de recherche, les liens qu’elles délivrent ne sont pas pris en compte ; la page demeure donc orpheline pour Google.
Identifier les pages orphelines
Passons maintenant à l’identification des pages orphelines sur votre site.
Une possibilité est de passer par Screaming Frog pour détecter les pages qui ne sont pas accessibles par des liens internes.
Pour cela, veillez à connecter votre GSC et à cocher cette option dans Search Analytics :
")
Cela permet de comparer les pages connues de Google et les pages internes du site. Ajoutez également les sitemaps du site en cochant cette option et en ajoutant des sitemaps spécifiques s’ils ne sont pas dans le robots.txt. Là encore cela permettra d’identifier des URLs qui ne sont pas forcément accessibles depuis un crawl de la home.

La majorité des filtres de SEO Spider sont disponibles en temps réel pendant l’exploration. Cependant, les filtres « URL orphelines » sous les onglets « Sitemaps » et « Search Console » ne peuvent être affichés qu’à la fin d’un crawl.
Ils nécessitent une analyse post-crawl pour être alimentés en données.

Vous pouvez retrouver les pages orphelines via les filtres GSC et Sitemaps sur la droite. Si les pages sont nombreuses, vous pouvez également tout exporter via Rapports – Pages orphelines.

Le problème avec cette approche est lié à mon avertissement un peu plus haut sur les liens depuis des pages non indexées.
Screaming Frog calcule toujours le Link Score sur l’ensemble des URLs crawlées et il n’est pas possible de filtrer le calcul pour ne prendre en compte que les pages indexées.
Pour contourner cela, vous pouvez supprimer les pages non indexées du crawl en sélectionnant toutes les lignes concernées puis « clic droit » – « retirer ».
Relancez une analyse du crawl et vous aurez alors une meilleure idée des pages orphelines, car nous avons retiré de l’analyse toutes les pages qui peuvent faire des liens qui ne seraient pas considérés.
Attention néanmoins, vous n’aurez plus que des pages indexables et indexées dans votre rapport !
Comment corriger les pages orphelines
Pour régler le problème des pages orphelines, quelques étapes :
- Déterminez si la page doit continuer d’exister. Parfois il faut simplement la supprimer et la rediriger car elle était temporaire.
- Ajoutez des liens internes vers cette page, reprenez la méthodologie du choix des ancres pour éviter de devoir revenir corriger des erreurs plus tard. Retenez qu’une page qui a vocation à ranker devrait avoir au minimum 7 – 11 liens sur des ancres distinctes pour maximiser son potentiel.
- Assurez-vous d’avoir ces pages dans votre sitemap
- Une fois ces corrections faites, demandez une indexation à Google pour accélérer le processus

Comment optimiser le maillage d’une page spécifique
Quand on veut optimiser le maillage d’une page plusieurs points de départ existent :
- Je suis en train de créer une nouvelle page et je veux faire les choses bien
- Ma page existe déjà et je souhaite l’améliorer
Ensuite on a 2 objectifs possibles (non exclusifs, il faut souvent reprendre les deux)
- Je souhaite augmenter le nombre de liens vers cette page pour augmenter son PR
- Je souhaite trouver les meilleures ancres pour varier la sémantique pointant vers la page et maximiser sa visibilité
1 – Optimiser le maillage interne d’une nouvelle page
Dans ce cas on sait déjà que la page en question n’est pas publiée donc elle ne reçoit aucun lien et n’en émet aucun.
Pour un peu de contexte, notre exemple se basera sur le site e-commerce Protéalpes, qui propose de la whey sans édulcorants et sans additifs. Leur but est de pousser leurs fiches produits et pages catégories depuis les pages du blog.
Cette page a forcément un objectif, ici on prendra l’exemple de la requête « whey pour prise de masse » où l’on va expliquer les critères d’une protéine en poudre adaptée à cette phase de l’entraînement et comment faire son choix.
On commence par se rendre sur le dashboard de ThotSEO pour lancer notre analyse.

ThotSEO va maintenant sonder les concurrents et les pages wikipedia des différentes thématiques (whey & prise de masse ici) pour calculer les termes essentiels à une excellente page sur ce sujet.
Une fois l’analyse terminée, allez sur l’interface, qui a l’option “Maillage interne” sur la gauche.

Ici je vous conseille de tout de suite connecter votre GSC car cela sera très utile par la suite. Autrement vous pouvez renseignez le domaine (protealpes.com dans notre cas)
Notez que vous pouvez aussi travailler sur un sous-domaine spécifique. Par exemple pour protealpes.com les contenus relatifs à la prise de masse sont dans un sous-dossier particulier. Comme je souhaite essayer de garder cette section assez « étanche » je vais concentrer l’analyse sur ce sous-dossier dans un premier temps.

Une fois l’analyse terminée, vous obtenez les pages avec le meilleur glissement sémantique.

Pour pouvoir vous montrer la suite de ma méthodologie voici toutes les propositions issues de Thot. A présent nous avons à notre disposition plusieurs options pour mailler notre page.
- Nous allons intégrer entre 7 et 11 liens au coeur de notre contenu vers les autres pages éditoriales
- Nous devons ensuite insérer des liens VERS notre nouveau contenu depuis des pages existantes
Mais comment choisir quel lien faire vers et depuis où ? Au hasard ? Non !
| Score | Title tag | URL |
|---|---|---|
| 100% | Quelle est la meilleure whey en prise de masse ? | https://protealpes.com/prise-de-masse/meilleure-whey/ |
| 100% | Prise de masse sèche : quelle whey choisir ? | https://protealpes.com/prise-de-masse-seche-quelle-whey-choisir/ |
| 79% | Quand consommer ses protéines en prise de masse ? | https://protealpes.com/prise-de-masse/timing-gainer-prise-de-masse/ |
| 79% | Prise de masse : le guide complet pour les athlètes débutants | https://protealpes.com/prise-de-masse/ |
| 77% | Combien de protéines consommer par jour pour une prise de masse efficace en musculation ? | https://protealpes.com/prise-de-masse/quantite-proteines/ |
| 73% | Prise de masse chez la femme : nos conseils | https://protealpes.com/prise-de-masse/femme/ |
| 69% | Prise de masse : combien de temps prévoir ? | https://protealpes.com/prise-de-masse/duree/ |
| 69% | Dois-je manger plus souvent en prise de masse ? | https://protealpes.com/prise-de-masse/frequence-repas/ |
| 68% | 14 délicieuses recettes de shakers protéinés pour prise de masse | https://protealpes.com/prise-de-masse/recettes-shakers/ |
| 66% | Quels aliments privilégier pour grossir et prendre du poids ? | https://protealpes.com/prise-de-masse/aliments-a-privilegier-pour-prendre-du-poids/ |
| 59% | 4 programmes alimentaires pour la prise de masse | https://protealpes.com/prise-de-masse/programme-alimentaire/ |
| 59% | Nutrition et prise de masse pour débutant : 15 conseils | https://protealpes.com/prise-de-masse/nutrition-pour-debutant/ |
| 56% | Quelle quantité de graisses est nécessaire pour la prise de masse ? | https://protealpes.com/prise-de-masse/graisses-prise-de-masse/ |
| 52% | Prise de masse ectomorphe : alimentation, conseils, planning | https://protealpes.com/prise-de-masse/prise-de-masse-ectomorphe/ |
| 51% | Comment calculer mes besoins caloriques pour la prise de masse ? | https://protealpes.com/prise-de-masse/besoins-caloriques/ |
Premièrement on va déjà s’assurer que notre contenu fait bien des liens sortants vers les pages que l’on souhaite pousser en priorité : nos pages produits et notre page catégorie.
Ensuite nous devons revenir à notre schéma de maillage :
A-t-on une stratégie bien définie ? Est-ce un cocon sémantique ? Un maillage circulaire ? Un maillage avant tout axé conversion ?
Dans notre cas, il n’y a pas de stratégie fixe. Autrement dit nous sommes dans une optique de conversion pour les utilisateurs prêts et d’éducation et de progression pour les autres.
Il nous faut nous poser la question du chemin de l’utilisateur pour déterminer quel lien faire vers où.
La méthode est très simple, parcourez les lignes du tableau et demandez-vous :
“Si une ou un internaute est sur ma page, est-ce que ça le rapproche de la conversion s’il se rend sur l’une de ces pages ?”
💡 L’objectif est vraiment de faire progresser notre lecteur dans sa quête d’information vers notre objectif.
Par exemple, ma page « Quelle whey choisir pour un prise de masse sèche » vient APRES dans le processus de réflexion. La question est spécifique à la prise de masse « sèche » on est donc déjà donc plus loin dans la réflexion après avoir vu les bases.
On a pas vraiment besoin de le faire à chaque fois quand on connaît ses sujets mais pour la démonstration voici le tableau avec la position de chaque sujet par rapport à notre page actuelle.
| Title | Position | Justification |
|---|---|---|
| Quelle est la meilleure whey en prise de masse ? | APRES | Après avoir compris comment choisir une whey, l’étape suivante est de déterminer la « meilleure ». |
| Prise de masse sèche : quelle whey choisir ? | APRES | Spécifique à la prise de masse sèche : on va plus loin dans la réflexion après avoir vu les bases. |
| Quand consommer ses protéines en prise de masse ? | APRES | Le timing de consommation vient en général après le choix du type de protéine (dont la whey). |
| Prise de masse : le guide complet pour les athlètes débutants | AVANT | C’est une introduction générale à la prise de masse, on lira ensuite un contenu plus précis sur la whey. |
| Combien de protéines consommer par jour pour une prise de masse efficace en musculation ? | AVANT | Avant de choisir une whey, on se renseigne d’abord sur la quantité globale de protéines à consommer. |
| Prise de masse chez la femme : nos conseils | AVANT | Page plus généraliste (focus femme) qui précède la question précise du choix de la whey. |
| Prise de masse : combien de temps prévoir ? | AVANT | Le calcul du temps global fait partie des bases avant d’entrer dans le choix précis de la whey. |
| Dois-je manger plus souvent en prise de masse ? | AVANT | Autre question de base sur la stratégie globale de prise de masse, avant de se focaliser sur une protéine. |
| 14 délicieuses recettes de shakers protéinés pour prise de masse | APRES | Les recettes arrivent après avoir choisi sa protéine (dont la whey). C’est un prolongement pratique. |
| Quels aliments privilégier pour grossir et prendre du poids ? | AVANT | Page sur la nutrition globale, en amont du choix spécifique de la whey. |
| 4 programmes alimentaires pour la prise de masse | AVANT | Présentation de plans alimentaires globaux, donc avant la décision précise sur la whey. |
| Nutrition et prise de masse pour débutant : 15 conseils | AVANT | Guide général pour débuter la prise de masse, on passe ensuite au choix de la whey. |
| Quelle quantité de graisses est nécessaire pour la prise de masse ? | AVANT | Fait partie des bases en macro-nutrition, donc avant le choix de la whey. |
| Prise de masse ectomorphe : alimentation, conseils, planning | AVANT | Approche globale pour un profil spécifique (ectomorphe). Ensuite, on découvre quelle protéine choisir. |
| Comment calculer mes besoins caloriques pour la prise de masse ? | AVANT | Calculer ses apports globaux (calories, macros) est un prérequis à la sélection d’un produit protéiné précis. |
On sait à présent VERS quelles pages faire des liens depuis notre contenu actuel et DEPUIS lesquelles mailler notre nouvelle page.

A présent il nous faut déterminer les ancres que nous allons utiliser dans notre nouveau contenu pour pointer vers nos pages APRES.
Pour cela on retourne dans notre espace Thot dans l’onglet maillage interne. De là, cliquez sur « Obtenir des suggestions d’ancres » et patientez 10 secondes.

En quelques instants vous aurez pour chaque page de la liste une série d’ancres de liens potentielles triées par potentiel. Evidemment certaines doivent être modifiées pour en faire une suite de mots correcte mais vous ne manquerez plus jamais d’idées.

Maintenant que notre page est publiée, il nous faut à présent la mailler depuis nos pages « AVANT ». On ne peut pas se baser sur la GSC pour trouver des idées d’ancres il faut donc :
- se creuser la tête (ou plutôt se mettre dans celle de sa cible)
- utiliser des outils tiers
Le plus simple est de partir d’une liste de termes proche de la requête que l’on vise. Par exemple :
- choisir sa whey en prise de masse
- quelle whey en prise de masse
- …
On va aussi pouvoir se baser sur les requêtes pour lesquelles nos concurrents se positionnent avec la page actuellement rankée. Pour cela Ranxplorer est sans aucun doute le meilleur outil FR.
Mettez les 1ères URLs de la SERP dans l’outil pour découvrir sur quelles requêtes elles se positionnent et utilisez-les en base d’idées.

2 – Améliorer le maillage interne d’une page existante
L’étendue de ce chantier va dépendre de l’état de l’existant.
Là encore on va pouvoir au choix ajouter des liens vers cette page, diversifier les ancres ou les deux simultanément.
Partons du principe que vous disposez d’une page dont il faut faire les deux.
Pour notre exemple ce sera notre page sur les dangers de la Clear Whey (une whey bien marketée mais qui flingue l’organisme à cause de son acidité extrême) donc l’url est : https://protealpes.com/clear-whey/
Cette page ne dispose que de 4 liens entrants uniques (dont 1 seul contextualisé, les 3 autres sont le sitemap, le blog et une page catégorie du blog)
Autrement dit, c’est sans surprise qu’elle peine à se positionner dans les SERPs et à amener du clic.

Le début de notre process commence de manière similaire avec une analyse ThotSEO où l’on va renseigner notre URL.
")
Ensuite depuis notre onglet maillage interne ou va lancer une nouvelle analyse mais en renseignant l’url de notre page.

De là on retrouve nos suggestions de liens internes mais avec une petite subtilité. Afin de ne pas doubler les liens, Thot nous indique si chaque page :
- fait un lien VERS mon contenu actuel (lien vers)
- reçoit un lien depuis mon contenu actuel (lien depuis)
Dans notre cas il n’y a aucun lien depuis car comme nous l’avons vu ma page n’est quasiment pas liée depuis le reste du site.

A partir de ce point la suite est similaire. On intègre les liens en suivant notre stratégie de maillage et en sélectionnant des ancres variées, optimisées et précises.
Pour ajouter des liens vers mon contenu Clear Whey je vais suivre le même chemin de réflexion pour chaque lien proposé : est-ce que ce sujet vient logiquement AVANT ou APRES dans la réflexion de ma cible.
Si je décide que ma page « La whey est-elle dangereuse pour le coeur » vient AVANT j’ai une bonne candidate pour ajouter un lien vers ma page Clear Whey.
Pour ce qui est de l’ancrage je me rends sur la GSC pour observer les requêtes existantes en top 20 avec des impressions intéressantes.
Je vous rappelle l’objectif : entre 7 et 11 liens minimum sur des ancres différentes, contextualisées et placées au coeur de paragraphes cohérents.

Remailler des pages existantes quand rien n’a été fait auparavant est très efficace mais c’est une tâche fastidieuse. Je vous conseille vivement de mettre le maillage au coeur de votre processus de rédaction pour ne pas avoir à revenir tous les 3 mois sur ce genre d’opération.

« Après avoir testé plusieurs outils, Thot est le plus clair et le plus simple d’utilisation.
L’interface est très intuitive et l’utilisation assez ludique grâces aux couleurs.
Petit coup de coeur pour les suggestions de maillage interne ultra pertinentes ! »
Clara Mongellaz
Copywriter, + de 100 articles à son actif sur Thot

Les différents modèles de maillage interne
- Canaliser le PageRank dans une seule page ?
- Maximiser la conversion en facilitant le parcours utilisateur ?
- Diffuser équitablement le PR au sein des pages ?
- Maximiser la navigation ?
Les modèles servent des objectifs distincts
Imaginons que nous ayons une landing page à pousser dans la SERP.
Celle-ci a besoin d’un maximum de PR interne, et comme c’est une page de conversion, on veut y amener nos visiteurs une fois qu’ils sont « mûrs ».
Si l’on s’appuie sur le modèle de maillage interne suivant, celui-ci n’est pas le plus adapté d’un point de vue PRi pur.
Dans notre exemple, nous démarrons avec notre page la plus importante qui concentre 6% du PageRank total.

Dans notre cas, une solution pourrait être de faire remonter le jus des pages vers notre page cible.
Pour ce faire, nous allons :
- réduire les liens entre filles et enfants, pour les faire remonter vers notre landing.
- retirer les liens réciproques entre toutes les pages.

C’est un bon début, mais nous pouvons tenter une approche différente avec les pages enfants, en amenant un maximum de liens de ces pages vers la landing (en vert).
Cela a un sens en termes de conversion, car un utilisateur sur une page du bas a peut-être eu la dernière réponse dont il avait besoin et est maintenant prêt à passer à la phase d’achat.

Cette optimisation est intéressante, mais nous pouvons encore améliorer notre score en fusionnant les deux méthodes.
On va :
- ajouter des liens depuis les pages enfants comme vu plus haut (les liens en verts).
- retirer tous les liens réciproques entre les pages de même niveau.
- supprimer les liaisons descendantes filles-enfants.
Notez comme à présent il n’y a plus que des boucles sans retour en arrière possible.

L’étape suivante est d’ajouter une page amplificatrice qui fait un lien réciproque vers la page cible. Le but de cette page est de concentrer un maximum de link juice vers la landing. L’impact est immédiat !

La dernière brique (optionnelle) est d’ajouter un maximum de liens des pages intermédiaires et mixtes vers la page boost. La puissance donnée par la page amplificatrice est bien supérieure à une approche de liens intermédiaires qui se lient à la landing.
Attention néanmoins, avec cette approche toutes les pages qui ne sont pas la landing ou la page boost sont vidées de leur PRi et auront beaucoup moins de chances de se positionner.

À l’origine, nous avions 6% du PageRank concentré sur une seule page. Maintenant, si l’on additionne la page boost et la landing, nous sommes à 79%.
Et pour pouvoir utiliser la page amplificatrice dans les meilleures dispositions, il faut qu’elle vise une requête stratégique et qu’elle soit optimisée pour convertir.
Si l’on prend l’exemple du site de Protéalpes pour la requête “whey prise de masse” :
- La page amplificatrice serait un guide pour choisir sa whey en PDM ou une page listant les différents avis sur les produits Protéalpes.
- La page mère serait la page catégorie avec des wheys protéines.
Mais cette solution n’est pas parfaite, les pages intermédiaires étant quasiment vides de PageRank si elles ne reçoivent aucun lien interne et aucun backlink.
Pour contrer cela, il y a deux options (non exhaustives) :
Option 1 : Faire des backlinks sur les pages du bas pour refaire circuler le jus vers la page cible tout en renforçant l’ensemble des pages.
")
Option 2 : Intégrer ce cocon comme un bloc dans le site et le mailler avec soin. On peut par exemple mailler les pages de niveau 2 depuis la home et/ou les pages de niveau 3 aux catégories.
On garde ainsi une profondeur proportionnelle à l’importance de nos pages, tout en perfusant du PRi dans notre ensemble de pages.

Il reste difficile d’appliquer à la lettre ces recommandations et cela reste l’une des nombreuses options du maillage interne. Dans cet exemple, on ne prend pas à 100% la logique de conversion de l’utilisateur, car le but est de faire circuler un maximum de PageRank sur une page donnée.
Évidemment, il existe quantité de possibilités en fonction des objectifs de votre site.
Creusons en peu plus le sujet des modèles de maillage en faisant appel à un spécialiste du maillage interne, Dan Bernier.

Selon lui, il existe actuellement cinq modèles qui sont réellement utilisés par les sites web.
Les différents modèles reconnus
Il y a tout d’abord le cocon sémantique et son architecture maintenant bien connue, créé par Laurent Bourrelly. La stratégie va au-delà du maillage, mais si l’on se concentre sur cet aspect, voilà une représentation basique.
")
Dans ce modèle, la position des liens au coeur des pages à une grande importance.
- Les liens vers les pages de niveau supérieur seront en haut du contenu.
- Les liens vers les pages de niveau inférieur sont au coeur du contenu.
- Les liens vers les pages de même niveau sont en bas de page.

Le modèle du topic cluster, créé et popularisé par Hubspot dès 2013, et repris par Samuel Schmitt en 2018.

Le modèle de maillage interne du silo créé par Bruce Clay et popularisé par inLinks en 2020. Il se distingue du cocon sémantique « classique » par le bouclage entre les publications de toutes les catégories.

Le modèle de maillage circulaire (ou du 3ème type), théorisé par Christian Méline en 2020. Il consiste à constamment faire découvrir de nouvelles pages au crawler, sans qu’il retourne sur les pages existantes. Avec ce modèle, le but est de faire ranker toutes les pages, et ne pas concentrer tout le PageRank sur quelques unes.
Ce concept va à l’encontre du processus de cocon sémantique traditionnel en supprimant les liens réciproques tout en forçant notre surfeur raisonnable à avoir un comportement précis lors de sa visite. C’est le modèle le plus intéressant pour les crawlers, même s’il reste complexe à mettre en place sur un site web.
Dans un article sur Reacteur, Christian Méline décrit la puissance progressive d’un lien. Pour qu’il « libère » toute sa puissance, le surfeur de Google doit le suivre environ 40 fois. Au-delà de ce seuil, l’effet se stabilise et ne s’intensifie pas significativement, avant d’atteindre un plafonnement à 100 itérations (sauf si la page source change).
D’où l’importance d’un maillage interne bien conçu pour maximiser l’impact de chaque lien.

Enfin, le modèle de maillage interne du silo circulaire, popularisé par Constantin Oesterling en 2021. C’est un modèle particulièrement intéressant pour de la conversion, car on s’assure que l’utilisateur ira vers les pages commerciales. Pour de l’optimisation de PageRank en revanche, il faudra privilégier une autre approche.

Pour retrouver ces cinq modèles, vous pouvez regarder cette conférence de Dan sur Youtube.
Le coeur de son intervention porte sur le choix du modèle, et sur l’impossibilité de répondre parfaitement à la fois aux algorithmes des moteurs et aux internautes.
Et donc, on en reste là ? Pas tout à fait. Afin d’avoir un modèle de maillage qui se rapproche du comportement des utilisateurs, Dan a imaginé quelque chose de différent 🔽

Pour bien se représenter le parcours d’un internaute dans un modèle comme celui-ci, prenons comme exemple une personne qui souhaite faire du camping dans le Verdon :
- L’internaute lance sa recherche initiale sur « meilleurs campings dans les gorges du Verdon » : il fait une requête informationnelle et atterrit sur l’article de blog d’un camping. Ce dernier détaille les spots où camper avec des conseils pratiques.
- Il parcourt la page et clique sur un lien interne en haut de page qui le renvoie vers une page commerciale présentant les caractéristiques du lieu : emplacements, bungalows, piscine, activités…
- Après avoir exploré les options d’hébergement, le visiteur va rejoindre une page transactionnelle via un nouveau lien en haut de page.
- Cette dernière le convainc de passer à l’action, il clique sur un CTA et rejoint la dernière étape de son parcours, la page d’action. Il y complète sa réservation en ligne.
Cet exemple simplifié permet de se représenter une vision d’ensemble de la manière dont les internautes vont naviguer sur un site dans ce genre de configuration.
Le but du maillage reste de construire et transmettre son autorité. Et pour Dan, il y en a trois types :
- Avoir un maximum de backlinks pour le « score de confiance ».
- Miser sur de très nombreux contenus de qualité pour prouver l’expertise.
- Analyser le comportement de l’internaute pour connaître ses habitudes et envoyer un signal positif à Google : plus un visiteur passe de temps sur notre site et visite des pages, plus le moteur y donnera du crédit. Pour connaître le comportement des internautes, la carte de chaleur est une possibilité.
Cependant, mesurer directement l’impact de notre modèle sur l’atteinte des objectifs de notre site est impossible en l’état. Dans ce cas, comment faire ? Une approche est d’optimiser plusieurs pages dans une logique de test and learn, puis d’observer les retombées potentielles durant plusieurs semaines.
Quel est le meilleur modèle ?
Pour aller plus loin dans la compréhension des modèles de maillage présentés et pour faire une comparaison de PRi, vous pouvez faire un tour sur le simulateur de diffusion de PageRank de Thot.
Créez vos propres pages ou partez d’une structure pour vous projeter sur la manière dont le PageRank va être partagé entre les pages de votre site.
Vous pouvez également préciser le modèle depuis l’interface : surfeur aléatoire ou surfeur raisonnable.
+ si vos liens sont en nofollow, obfusqués, dans le contenu ou dans le header, la sidebar, le footer…

Pour démarrer, voici une représentation du cocon sémantique. Par simplification, tous les liens sont considérés comme étant dans le contenu, mais sur le simulateur, vous pouvez placer des liens dans le header, le footer… comme nous venons de le voir juste au-dessus.
Ici nous testerons les différents modèles en surfeur raisonnable. Par souci d’égalité, ils sont parfois légèrement modifiés pour avoir entre 10 et 12 pages.

Comparons cette simulation de PRi avec le modèle de Hubspot, le topic cluster.
La théorie du topic cluster n’est pas aussi rigide que pour le cocon. On parle de « liens entre les pages pertinentes » mais sans règles précises de maillage.
Voyons une première version simple telle qu’on la retrouve souvent dans les schémas de Hubspot, Semrush ou Thruuu.

Dans cette représentation la page pillier concentre 50% du PRi. C’est un score honorable mais en pratique pas très user friendly pour aller de sujet en sujet.
Si l’on rajoute des liens réciproques entre les pages voisines la page centrale s’affaiblie de moitié.

On peut tester différentes version du topic cluster. Si l’on ajoute des liens réciproques entre les pages voisines + 1 on perd encore 50% du PRi vers la page centrale.

Quoi qu’il en soit on n’est pas sur le même niveau de puissance que le cocon. Quid du modèle de Bruce Clay ?

Il y a plus de partage entre les pages avec celui-ci. Intéressant si la home n’a pas de vocation à se référencer et que l’on concentre la stratégie vers les pages catégories.
Voyons à présent le modèle théorisé par Christian Méline où l’on supprime les liens réciproques.

Le maillage du 3ème type est un modèle plus complexe à mettre en place, mais il permet un partage de PageRank équitable entre chaque page. Voyons maintenant le silo circulaire d’Oesterling.

Avec ce modèle, nous avons une concentration plus forte vers la page commerciale, qui communique aux autres pages via une page support. Cependant, les autres pages n’héritent que de peu de puissance.
Enfin, une représentation simplifiée du modèle imaginé par Dan Bernier, qui correspond à la fois aux attentes des algorithmes et des internautes.
Ici il n’y a pas forcément une page visée en priorité donc la comparaison a moins de sens.

La partie suivante devrait vous éclairer un peu plus sur le meilleur modèle dans VOTRE cas.
Comment choisir son modèle de maillage interne ?
La base, c’est de réfléchir à son objectif.
Un site e-commerce, une mutuelle ou encore un SaaS n’auront pas les mêmes besoins pour l’organisation des liens internes, même si les 3 visent la conversion.
Si l’on reprend les modèles de maillage que nous venons de voir, on peut donner un exemple d’usage pour chacun d’eux.
- Dans le cas où vos pages éditoriales sont toutes en capacité d’amener vers la conversion, préférez le maillage du 3ème type de Christian Méline en y intégrant des CTAs adaptés (potentiellement via des liens obfusqués).
- Si votre but est d’amener directement vers la page de conversion, le modèle d’Oesterling est tout trouvé.
- Au contraire, si vous avez besoin de faire progresser l’utilisateur par une montée en compétences, le cocon sémantique traditionnel est ce qui correspondra le mieux.
Le modèle du topic cluster, de Hubspot, est quant à lui davantage orienté pour les pages éditoriales. Pour agir sur la conversion, le mieux reste de placer votre produit ou service à pousser directement dans ces pages-là via des screens ou des demandes de démos.
Une fois que le modèle est défini débute la phase d’adaptation à la réalité de notre site :
- Analyse de l’existant ;
- Conception d’un schéma possible ;
- Scénarios de maillage et des chemins de conversions.
Tout ce travail en amont permet de concevoir la manière dont les futurs visiteurs vont naviguer entre les pages.
Est-ce que ce processus peut être automatisé ? Des outils comme Gephi et Cocon.se peuvent aider à visualiser son architecture interne, mais il n’existe pas d’automatisation pour créer un maillage parfait en quelques clics.
Pour récapituler…
| Modèle | Objectif(s) principal(aux) | Caractéristiques clés | Avantages | Inconvénients |
|---|---|---|---|---|
| Cocon sémantique (Laurent Bourrelly) |
Faire progresser l’utilisateur au fil de pages « parents → enfants → frères ». Structurer le contenu en silos rigoureux. Visée éditoriale et montée en compétence. |
Importance de la position des liens (haut pour les pages supérieures, au cœur pour les inférieures, bas pour les pages de même niveau). Architecture en branches thématiques, liens internes verticaux + horizontaux ciblés. Pensé pour faire remonter la sémantique et guider l’internaute. |
Meilleure progression utilisateur (pédagogique). Bon pour un contenu éditorial dense et structuré. Renforce la cohérence thématique. |
Mise en place parfois complexe (il faut bien distinguer les niveaux et gérer leurs liens). Peut être moins adapté si on veut pousser une page unique ou concentrer fortement le PageRank. |
| Topic cluster (Hubspot) |
Regrouper des contenus autour d’une « page pilier ». Viser le référencement global d’un sujet large. Maillage éditorial souple. |
Une page pilier au centre, liens depuis/pour des sous-pages connexes. Possibilité de liens réciproques ou non, selon l’objectif (fortifier la page pilier ou diffuser le jus). |
Flexible, moins de règles figées qu’un cocon. Idéal pour un large spectre éditorial (blog, guides…). Bonne lisibilité pour l’utilisateur. |
Si on multiplie les liens réciproques entre sous-pages, on dilue la page pilier. Moins “puissant” que le cocon pour booster une seule page clé. |
| Silo (Bruce Clay / inLinks) |
Segmenter le site en grands thèmes (catégories). Faciliter la navigation et l’indexation (architecture claire). Viser un référencement équilibré par section. |
Architecture en catégories distinctes, peu de liens entre les silos pour ne pas mélanger les thématiques. La home transmet du jus surtout vers les pages-catégories, qui le relayent ensuite vers leurs pages enfants. |
Très lisible pour Google et l’utilisateur. Convient bien aux sites e-commerce ou multi-thématiques (chaque section est “indépendante”). Partage d’autorité correct au sein de chaque silo. |
Peut cloisonner à l’excès et limiter la diffusion de PageRank d’une catégorie à l’autre. Nécessite une arborescence très structurée dès le départ. |
| Maillage circulaire (« 3ème type » - Christian Méline) |
Diffuser le PR de manière équitable sur l’ensemble des pages. Maximiser l’exploration (le crawler ne repasse pas sur les mêmes pages). Optimiser pour que toutes les pages puissent ranker. |
Supprime la plupart des liens réciproques (on « avance » toujours vers de nouvelles pages). Le Surfeur Raisonnable suit un chemin sans revenir en arrière, ce qui améliore la répartition du jus. |
Distribution plus homogène du PageRank. Bonne découverte de nouvelles pages par le crawler. Intéressant si toutes les pages peuvent convertir. |
Complexe à mettre en place à grande échelle (structure linéaire ou quasi-linéaire). Peut sembler moins naturel pour la navigation humaine (pas de retour évident). |
| Silo circulaire (Constantin Oesterling) |
Maximiser la conversion en menant l’utilisateur vers une page commerciale cible. Conserver une hiérarchie, mais avec un système de renvoi « en boucle ». |
Combine une approche “silo” avec des pages supports qui renvoient vers la page commerciale (landing), créant une boucle. Vise à pousser fortement la page de conversion, parfois au détriment du reste. |
Très efficace pour mettre en avant une ou deux pages clés (ex. pages transactionnelles). L’utilisateur est « guidé » naturellement vers l’offre commerciale. |
Les autres pages reçoivent peu de jus. Moins efficace pour ranker le reste du site. Peut frustrer l’internaute si la navigation est trop orientée “vente”. |
| Modèle “hybride” (Dan Bernier) |
Trouver un compromis entre SEO pur (PR) et UX (parcours utilisateur). Faire évoluer l’internaute d’un contenu informatif à une page d’action (conversion). |
Permet plusieurs “étages” : blog (info) → page commerciale (argumentaire) → page transactionnelle. Cherche à optimiser le comportement réel de l’utilisateur (clics, temps passé) tout en maintenant une structure SEO efficace. |
S’adapte mieux au comportement de recherche réel (information → décision → action). Peut soutenir le référencement global tout en favorisant la conversion. |
Demande une bonne connaissance du tunnel de conversion et du comportement utilisateur. La mise en place peut devenir complexe s’il y a de multiples cibles ou parcours. |
Plus que par typologie de site, on peut lier le choix de notre modèle à notre objectif.
- Canaliser le PageRank dans une page unique : privilégier un silo circulaire ou un cocon sémantique très orienté vers la page cible (avec peu de liens horizontaux). On peut aussi ajouter une page boost comme nous l’avons vu en haut de cette section.
- Diffuser équitablement le PR à toutes les pages : le maillage circulaire est le plus adapté.
- Faciliter la conversion et le parcours utilisateur : un modèle hybride ou un silo circulaire peut guider l’internaute vers la page transactionnelle.
- Faire monter progressivement l’utilisateur en compétence : le cocon sémantique ou un topic cluster bien réalisés apportent un cheminement didactique.
Ces modèles peuvent aussi se combiner partiellement (ex. un silo classique pour les catégories, agrémenté d’un mini-cocon sémantique sur un sujet sensible), à condition de bien réfléchir aux objectifs et à la cohérence globale du site.
Faut-il toujours mailler son contenu selon un modèle de maillage ?
Non, pour plusieurs raisons.
1 – Les modèles de maillage vu ici visent à amplifier et à canaliser la popularité d’un site : une reprise du maillage interne OU la mise en place d’un nouvel ensemble de pages avec une structure précise est donc surtout pertinent quand on dispose déjà de popularité à amplifier.
2 – Par ailleurs, si l’on manque du budget suffisant ou si l’on obtient déjà assez de liens externes pour se positionner, le retour sur investissement d’une refonte du maillage peut être limité.
Un maillage interne efficace demande du temps et des contenus. Sans ces ressources, mieux vaut une approche simple mais cohérente qu’un système incomplet.
Pour des requêtes à faible concurrence, une structure basique avec quelques principes fondamentaux de maillage peut amplement suffire.
Retenez que :
- les boucles sont importantes,
- qu’il faut pousser les pages importantes via des ancres internes variées et optimisées,
- dans des zones où l’utilisateur a des chances de les cliquer.
3 – De plus, si votre site peut encore gagner en visibilité grâce à des backlinks de qualité, cette voie mérite priorité. Pour certaines requêtes, quelques backlinks stratégiques suffisent à positionner votre contenu en première page, rendant superflu un travail approfondi de liens internes avec la création de dizaines de pages.
Cela étant dit, si vous partez de 0 s’orienter vers un modèle spécifique dès le début vous épargnera une reprise à grande échelle dans quelques mois ou année.
De plus, ce n’est pas parce qu’il ne faut pas obligatoirement faire une fixette sur un maillage qu’un audit de l’existant n’est pas indispensable.
Des outils comme Gephi sont difficiles à prendre en main mais ouvrent la porte à une bien meilleure compréhension de l’état d’un site.

Cela va aussi vous permettre de tester différentes stratégies et leurs impacts avant de les implémenter.
N’hésitez pas à nous faire savoir si un cours complet sur Gephi + Screaming Frog peut vous intéresser.

Conclusion
Nous arrivons au terme de cette bible du maillage interne, un guide qui, nous l’espérons, vous aura fourni les clés pour transformer votre approche des liens internes en 2025.
Le maillage interne n’est pas un simple détail technique, mais bien un levier fondamental que vous maîtrisez à 100%. A vous d’en faire bon usage en exploitant les bons outils.
À travers cette exploration, nous avons couvert l’essentiel : des définitions de base aux erreurs critiques à éviter, en passant par les modèles de maillage adaptés à chaque objectif et les méthodes d’optimisation ciblées.
Rappelez-vous ces points essentiels :
- La diversité des ancres est cruciale pour maximiser votre visibilité
- La direction stratégique des liens détermine la distribution du PageRank
- L’intégration de CTAs adaptés à chaque niveau d’engagement transforme votre maillage en véritable outil de conversion
- Le choix du modèle de maillage doit s’aligner avec vos objectifs spécifiques
Un maillage interne bien pensé crée cette boucle vertueuse que nous avons évoquée en introduction : meilleur ROI de vos contenus, plus de ressources pour la qualité, et augmentation de vos conversions et revenus.
Ne voyez pas le maillage comme une tâche ponctuelle, mais comme une démarche continue qui évolue avec votre site. Chaque nouveau contenu est une opportunité de renforcer cette structure, chaque audit une chance d’identifier des optimisations potentielles.
Que vous soyez débutant ou expert en SEO, nous espérons que ce guide vous servira de référence pour transformer votre maillage interne en avantage compétitif durable.

Paul Grillet

Loïs Marchand

Thi Meï Tong
Ce guide 100% gratuit a nécessité plus de 159h de travail, pour le soutenir ➜











Vous êtes encore là ? Merci !