
Si vous êtes dans l’éco-système c’est impossible de ne pas avoir entendu parler de cet outil.
En octobre je vous ai promis de tester en profondeur l’outil RM Tech et vous faire un retour sur les impacts SEO réels constatés.
Alors pour me faire une idée de la pertinence de leurs recommandations Olivier et Fabien m’ont permis de faire un test intégral de leur solution.
Dans cette review je vais vous détailler tous les éléments qui sont ressortis, les points positifs comme négatifs et l’impact de ces actions.
Le site audité sera celui d’une marque que j’adore tout particulièrement : Protéalpes.
Suite à une refonte du site + la disparation de 3 liens site wide + l’arrêt des publications sur le blog, le site connaît une baisse de trafic de 20k à 17k clics par mois sur la Search Console.
Il nous faut corriger cela et l’objectif est de repartir sur une base technique saine.

Je vous préviens, il y a beaucoup d’infos, c’est souvent le cas quand on a affaire à une équipe aussi technique. Heureusement en cas de questions le support ultra réactif

Pour bien suivre les impacts de toutes nos actions on va utiliser un module très utile de RM Console : le suivi d’action.
Le principe est simple : on renseigne n’importe quelle action SEO, les pages ou les requêtes impactées (ou les deux) ainsi qu’une durée de test et patiente.
A la fin du test RM Console nous donne de super informations sur l’impact réel de chaque action.

Et par exemple si je clique sur mon action SEO “28 liens bas de gamme vers 3 pages produits” j’ai une grande quantité d’information croustillante. Toutes ne sont pas toujours utiles mais au moins tout y est.
Si vous souhaitez simplement lire ma conclusion, scrollez jusqu’en bas.
Bon commençons.
Lancement de l’audit
Le lancement se fait en 7 petites étapes et est globalement c’est très bien guidé. On sélectionne l’url de départ, on connecte la Search Console tiers… bref rien de compliqué pour un audit simple.
Petite astuce quand même pour les sites utilisant un theme builder un peu lourd comme Divi. Par défaut RM Tech ne prend pas les pages supérieures à 700 ko, or la page d’accueil était plus lourde ce qui a causé une erreur lors du premier lancement.
Cette limite est justifiée, comme le précise Fabien la plupart du temps Bing ne télécharge que les 700 premiers Ko de la page, ce qui peut empêcher de voir du contenu et/ou des liens.
Pour résoudre cela vous pouvez modifier la taille max dans les paramètres avancés de l’étape 2 :

💡 Amélioration possible : Il serait intéressant d’aller vérifier cette première page avant le lancement de l’audit pour prévenir l’utilisateur et éviter les allers-retours, mais au pire le support m’a répondu dans les 5 minutes.
Découverte de l’audit
Une fois le crawl terminé on reçoit un mail nous prévenant de sa disponibilité.
Connecté, je constate le désastre :

L’objectif est de viser les 95% sur les deux indices, autrement dit il y a du boulot.
Juste en dessous on a un peu plus de détail via un graphique radar super sympa :

Bon il va nous falloir creuser tout cela, et visiblement il y a de quoi car sur la page récap je compte :
- 12 971 mots
- 19 mots par phrases
- 65 min de lecture
Heureusement il y a une synthèse au début pour nous résumer tout cela.

Let’s go, on attaque par la partie crawl et indexabilité.
Crawl et indexabilité
Premier point, je sais que le site a normalement 200 ou 300 pages max, mais l’audit en aurait crawlé plus de 2000…
Je check donc les sitemaps pour confirmer et on a bien un problème de cohérence entre ce qui est publié volontairement et ce qui est crawlé :

En vérifiant les urls concernées, une grande partie vient du module Woo Commerce qui ajoute un paramètre d’url pour l’ajout au panier.
Cela donne des centaines d’url du type : https://protealpes.com/produit/maltodextrine-neutre/?add-to-cart=9176
Je vais donc devoir supprimer toutes ces urls de l’index Google et empêcher leur crawl futur dans le robots.txt. J’en profite pour retirer d’autres pages qui n’ont rien à faire dans l’index Google via les lignes suivantes :
Disallow: /feed/
Disallow: /author/
Disallow: /tag/
Disallow: /*add-to-cart=*
Disallow: /*?add-to-cart=Ensuite, je vois dans la SearchConsole qu’une large part de ces URLs n’est pas indexée, mais il y en a tout de même…
Pour les supprimer de l’index je vais passer par l’API Google Search console, via le plugin RankMath :

Sous quelques semaines le résultat ne se fait pas attendre :
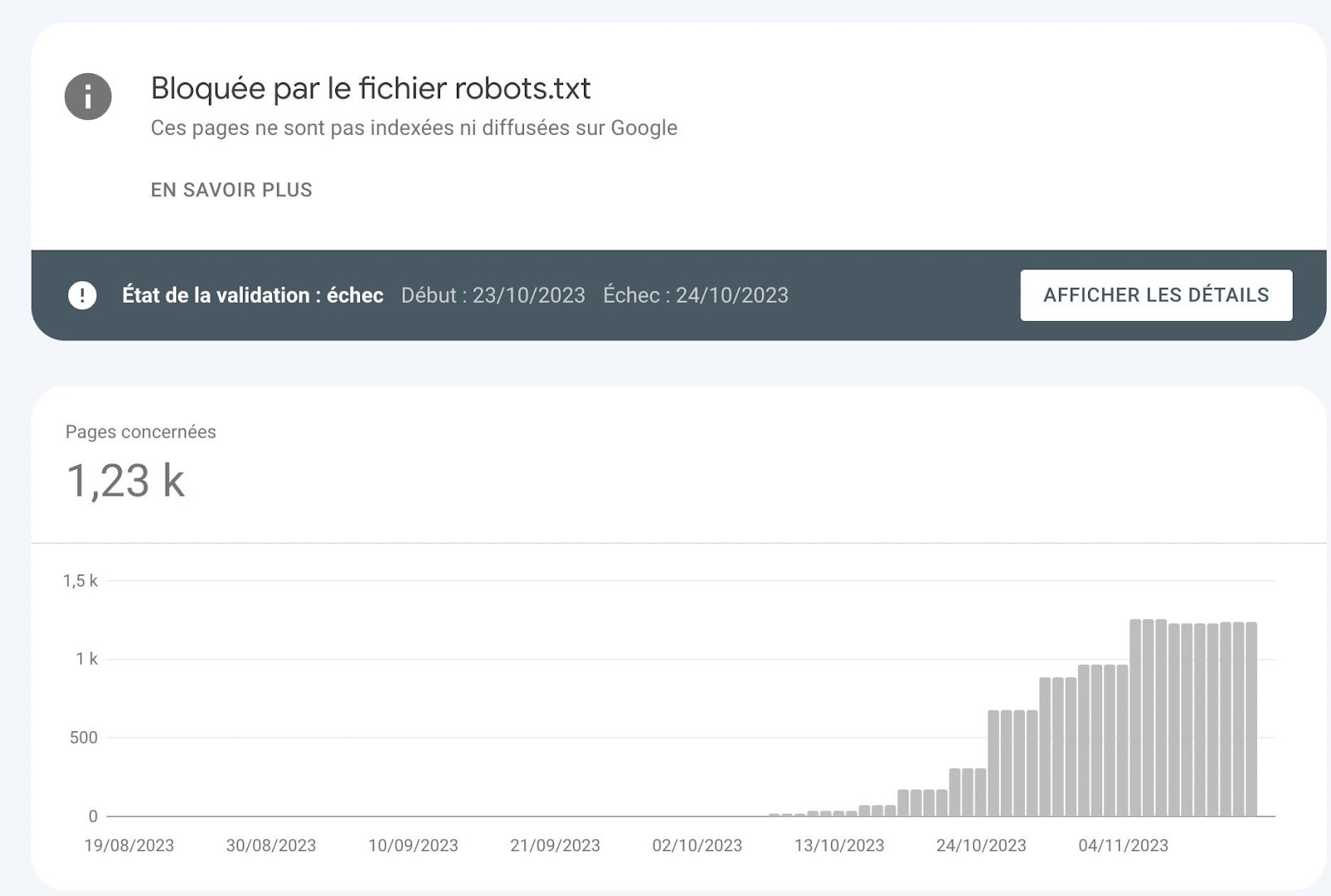
Néanmoins une large des part des urls indexées avec un paramètre le reste…

J’ai fais une seconde demande de suppression de ces pages via l’API car elles ne sont qu’un gaspillage de crawl qui ne génère vraiment rien :

Une fois la suppression demandée voici comment j’enregistre cette action, notez que j’ai rarement d’idées pour les améliorations… Ici n’est du nettoyage global.


J’ajoute la date, la durée et quelques autres éléments et hop, je serais prévenu dans 6 semaines des résultats.
Passons à présent à une autre partie des questions de crawl et d’indexabilité : les redirections.
Évidemment il en faut le moins possible. Vu la taille du site (< 500 urls) c’est plus pour envoyer un signal de qualité que pour économiser du budget crawl.
Voyons cela.
Gestion des redirections
RM Tech nous indique que plusieurs pages présentent des codes ≠ 200 et qu’il va nous falloir traiter ces urls.

J’ai tout rassemblé dans mon Google Sheet de travail en notant à chaque fois le problème concerné et je démarre le chantier :

Pour la correction le principe est assez basique : on retrouve les pages contenant les liens pointant vers l’url concernée puis on corrige (j’ai l’habitude avec Screaming Frog) :

Quand elles sont peu nombreuses certaines redirections se gèrent très facilement avec un remplacement des mauvaises URLs directement dans la page
Pour d’autres il faut aller modifier directement la base de données. Pour cela j’utilise le plugin Better Search And Replace (en faisant très très attention !).
Voici un petit exemple pour la redirection de la version en www vers celle sans.

Enfin pour l’image en erreur je ne savais pas vraiment où les modifier car je n’avais pas accès à cette image dans le thème…
Avec ChatGPT on trouve rapidement l’origine et la table à modifier :

Et hop l’url en erreur est modifiée, en un sens comme cette image était sur toutes les pages c’est plus de 300 redirections de gagnées !

Maintenant que ce travail de redirection est terminé je vais encore une fois rentrer cette action sur RM Console, plus par principe car c’est surtout pour améliorer la santé globale du site.
Passons à la phase suivante concernant la vitesse du site.
Temps de téléchargement
Ici en voyant le graphique on peut voir que c’est un des problèmes majeurs. Ou pas ?

La solution de Fabien et Olivier nous donne une répartition des pages problématiques sous forme de tableau. Pratique pour voir l’étendue du boulot.

Heureusement en voyant ce tableau j’avais eu une intuition qui s’est avérée juste et qui m’évite pas mal de travail : les pages trop lentes sont les pages qui n’ont pas vocation à être indexées.
En résolvant le problème d’indexation des URLs dans la première partie on a automatiquement coché cette case. Ce qui m’arrange car l’optimisation de la vitesse est vraiment la tâche la plus barbante à mon sens.
On va quand même vérifier cela.
Pour commencer j’ajoute l’Excel exporté sur mon Google Sheet de travail.
Ensuite je filtre en retirant toutes les pages qui sont désormais non indexables :
- les pages avec paramètre d’url non pertinent ;
- les pages de dossiers redirigés comme les pages author par exemple ;

Et hop on passe de 2148 pages à problèmes à seulement 9 dont 6 qui sont vraiment importantes.

D’ailleurs ici on peut voir que l’export a intégré 3 pages pourtant bloquées via la balise meta robots noindex.
Bon, pour deux pages, vu que leur système de cache fonctionne bien je vais passer immédiatement à la partie suivante.
Profondeur des pages
Bon sans surprise en crawlant 10x plus d’URLs que prévu il y a des problèmes de profondeur avec des pages à plus de 11 clics de la home…

81% de pages correctes ce n’est pas dégueu non plus.
Comme pour les temps de téléchargement on va exporter tout cela et regarder si ce point n’est pas résolu tout seul via le régime qu’on a imposé au site.

💡 Amélioration : j’ai cru qu’il n’y avait pas de dossier téléchargeable sur cette partie et que j’allais devoir me baser sur notre crawl screaming frog.
Comme pour la partie crawl et indexabilité il y a souvent des fichiers dans les sous-parties je n’avais pas vu que cette fois il me fallait descendre pour télécharger le fichier (après la section maillage interne).
Pour finir sur ce point je pense que l’équipe a une vraie plus value à contextualiser les messages affichés.
Par exemple ici le message d’attention est incohérent et ressort pourtant autant que le reste.

On pourrait vraiment bénéficier d’une présentation plus visuelle avec des codes couleurs et des éléments dépliables uniquement si besoin.
Est-ce que ce n’est pas plus lisible comme cela avec un encart et un élément dépliable au besoin (malgré le manque d’inspiration pour le message en vert) ?

Bon après un filtrage des pages désormais retirées de l’index on obtient seulement 10 pages qui sont trop profondes sans que cela soit vraiment dramatique.

L’impact sera probablement infime mais comme presque toutes les pages sont des produits donc ce sera très simple à résoudre :
- Pour les 4 gainers on va ajouter ces produits à la page catégorie actuellement en niveau 1 ;
- Pour les articles on va s’assurer qu’ils apparaissent sur le blog et ajouter quelques liens vers eux au besoin ;
- Pour les 3 pages d’achat en lot comme elles ne devraient pas exister on va donc les retirer ;
Et hop, environ 2 minutes pour les gainers !

Pour les pages d’articles comme je n’ai pas encore testé le module maillage interne de RM Console (c’est la section suivante) je vais conserver mes process actuels.
Pour commencer je vais ajouter des liens vers ma page “Comment adapter sa sèche aux sports d’endurance” et je lance une analyse sur la page à mailler en utilisant un terme assez large (vous pouvez aussi le faire sur un terme précis au besoin, cela dépend de l’objectif j’y reviendrai dans un tuto dédié) :

Ensuite je me rends sur l’analyse.
Je vais dans l’onglet maillage interne et je lance une analyse sur mon site (ici protealpes.com).
En 30 secondes j’obtiens une liste de pages pertinentes pour mon sujet :

Quelques indications concernant les messages en vert :
- lien vers cette page : ma page actuelle fait déjà un lien vers l’url proposée
- lien depuis cette page : la page proposée fait déjà un lien vers mon url actuelle (https://protealpes.com/comment-adapter-la-seche-aux-efforts-dendurance/)
Il me reste à décider depuis quelles pages vers des liens vers ma page en manque de liens internes.
Pour cela je vais essayer de réfléchir en me plaçant à la place de la cible et me demander depuis quelles pages est-il logique d’arriver et vers quelles pages est-il logique d’aller par la suite pour l’amener à l’achat ?
Pour ma page “Comment adapter sa sèche aux sports d’endurance” voici ce que je trouve pour les 20 suggestions de Thot :
| Sujet | Venir de ce sujet vers la page actuelle | Aller vers ce sujet depuis la page actuelle |
| Quelle whey prendre pour sécher ? | Oui | Oui |
| Prise de masse sèche : quelle whey choisir ? | Oui | Oui |
| Comment prévenir la perte de masse musculaire ? | Oui | Oui |
| Est-ce que la whey est obligatoire pour prendre du muscle ? | Oui | Non |
| Combien de temps faut-il aux muscles pour récupérer ? | Oui | Oui |
| Quelle protéine en poudre choisir pour un ectomorphe ? | Non | Oui |
| Qu’est-ce que la caséine et quand en consommer ? | Non | Non |
| Combien de shakers de whey par jour devez-vous prendre pour maximiser votre progression ? | Non | Oui |
| Prendre sa whey avant de manger, bonne idée ? | Non | Oui |
| Prendre la créatine avant ou après l’entraînement ? | Oui | Oui |
| Quand prendre son shaker de whey ? | Non | Oui |
| BCAA définition, quantité, timing, risques.. [guide complet] | Non | Oui |
| Comment maximiser la récupération et la prise de muscle ? | Oui | Non |
| Comment prendre de la whey ? | Oui | Oui |
| La whey fait-elle grossir ? Que dit la science ? | Non | Oui |
| Whey protein pour sécher – Protéalpes | Non | Oui |
Pour trouver les idées d’ancres je vais simplement dans la SearchConsole et je regarde les termes clés non utilisés comme ancre pour cette page.
Il me suffit à présent de me rendre sur les articles identifiés comme « en amont » et d’intégrer mes liens.
Ici on est dans sur une mission de réduction de la profondeur des pages, pas de maillage interne donc je ne vais pas rentrer plus en détail sur ce point, on le traitera juste après avec le module d’RM Console.
Après quelques ajouts, me voici avec seulement 4 pages encore problématiques car je dois valider un point avec l’équipe de ProtéAlpes.

Bien, maintenant que cela est terminé j’ajoute comme d’habitude l’action à RM Console en spécifiant les URLs concernées :

Passons à présent au maillage interne.
Maillage interne
Vous le savez le maillage interne est un des leviers les moins bien exploité du SEO.
Cette partie commence très bien en rappelant que même s’il faut au moins 1 lien entrant interne, c’est nettement insuffisant si cette page a des objectifs SEO.
La première chose que l’on voit est un graphique qui vient confirmer notre hypothèse : plus il y a de liens internes, plus il y a de clics avec un gros impact dès 5 liens.

Concernant les ancres, l’équipe RM Tech fait aussi très bien les choses.
On nous précise bien l’objectif d’avoir au moins une dizaine d’ancres différentes pour chaque page puis on nous donne un graphique TRES parlant.

On voit clairement que les pages avec peu de diversité (moins de 6 ancres différentes) génèrent peu de clics.
Il serait intéressant de pouvoir filtrer cela avec les pages ayant au moins X liens mais la conclusion est déjà assez claire : il faut diversifier.
Ma principale tache sera donc de m’assurer que toutes les pages reçoivent au moins 6 liens internes de 6 ancres différentes.
On pourrait dire 10 mais pour commencer c’est une tache suffisamment longue et ardue et les rendements au delà de 6 semblent moins flagrants.
Pour commencer je vais mettre toutes ces données issues de RM Tech dans mon beau Google Sheet :

A partir de là j’ai une liste des pages qui sont en manquent de liens ET de diversité. Il ne me reste plus qu’à attaquer le chantier.
Notez que je ne comprends pas trop comment la home peut n’avoir que 2 liens entrants, mais c’est à vérifier.
Pour les ancres j’ai un second onglet, toujours issu des données de RM Tech, pour faire la différence entre les ancres via attribut ALT et les ancres via texte.

On a en plus le nombre de fois ou chaque ancre est utilisée pour une page.
💡Idée amélioration : Ce qui serait vraiment top, c’est d’avoir une nouvelle colonne indiquant si une ancre est utilisée vers une autre page, ce serait d’une grande aide pour bâtir un maillage interne clair et éviter la cannibalisation.
Je l’ai donc ajouté une colonne avec une formule que vous pouvez copier pour faire d’une pierre deux coups :

En parlant des attributs Alt, je constate qu’un grand nombre d’attributs sont vides.
Pour ne pas avoir à faire tout cela à la main j’ai donc fais un petit plugin avec l’aide de chat GPT qui me liste toutes les images sans attribut ALT et qui me propose d’ajouter son titre en attribut.
On peut imaginer une version plus aboutie via l’api chat GPT mais pour mon usage actuel c’est suffisant car la majorité des images ont des titres descriptifs. Cela m’a prit environ 2h mais c’est un plugin que je pourrais utiliser sur d’autres sites.
Il me suffit de vérifier l’ancre proposée pour chaque image, tout sélectionner et c’est terminé (on parle quand même de 400 attributs ALT vident donc ça m’a prit un peu de temps de tout vérifier)

Bon à présent passons à la pratique. Je vais choisir une première page et tester le module de maillage interne de RM Console.
On va commencer par la page https://protealpes.com/combien-de-grammes-de-creatine-par-jour/ qui ne reçoit qu’un seul lien (et n’a donc qu’une seule ancre).
On se rend sur l’onglet maillage interne de la RM Console et on choisit l’audit sur lequel on souhaite s’appuyer.
Attention, il faut un audit récent ! Je me suis fait avoir en tardant trop et j’ai dû relancé un second audit.

A partir de là on peut choisir 3 options, les 3 sont vraiment pertinentes pour notre site donc on va toutes les essayer une à une.
Je commence par l’option “une page que j’ai identifiée avec un maillage interne trop faible”.
Après une quinzaine de minutes on reçoit un mail nous annonçant que les résultats sont disponibles.
RM Console nous liste des urls classées par score sur lesquelles ont peut ajouter un statut :
- A ignorer,
- A traiter
- Déjà Ajouté

Ce qui est top c’est que l’outil a déjà retiré les pages depuis lesquelles il y a déjà des liens.
En plus, si l’on passe 100% par l’outil il est ultra simple de suivre l’impact de nos actions :

L’objectif de la solution est sans doute de s’intégrer de plus en plus sur les process d’optimisation pour ne plus être qu’un outil d’audit. Cela va dans le bon sens mais me concernant l’UX est encore à améliorer pour réduire la friction et qu’il me soit simple de quitter mes process actuels.
Mon avis sur le module maillage interne
Concernant la pertinence des suggestions je trouve ici quelques bonnes idées mais connaissant un peu les articles du blog je pense qu’il y a mieux.
Évidemment je ne parle ici que de pertinence pure pour un lecteur.
Je ne prends pas en compte le nombre de lien entrants de chaque page, leur profondeur, leurs impressions actuelles…
Je ne sais pas exactement comme RM Console fait son score mais ces éléments rentrent probablement en ligne de compte.
Cela étant dit, sur Thot les résultats sont un peu plus centrés autour de la thématique de la créatine mais notez que lui ne prend pas en compte les éléments cités juste avant.

Ce que je note de génial en revanche, c’est la présence des données GSC sur la même page suivies des ancres actuelles, très utile pour choisir ses ancres de liens et éviter les redites.

Pour choisir mes ancres, je pense que l’outil peut encore beaucoup évoluer.
Ce qui serait top pour ces idées c’est une suggestion des ancres possibles pour chaque page présentée.
A ce jour voici ma méthode :
- Je sélectionne une ancre via les suggestions dans RM Console
- Je vérifie que cette ancre n’est pas déjà en place avant de l’implémenter

Personnellement voici comment je procéderai :
1 – Liste des requêtes ayant le plus de potentiel pour mon url (fortes impressions, positions < 20)
2 -Je retire celles qui sont mieux positionnées pour une autre url
3 – Je retire les stopwords
4 – Je sonde les pages identifiées comme pertinentes et je recherche les mentions de ces requêtes hors stopwords
Bon il est temps d’ajouter mon lien sur la page identifiée comme intéressante concernant le timing de la prise de créatine.
J’en profite pour organiser un peu mon tableau en regroupant les urls par catégorie de sujet, ça me permet de gagner beaucoup de temps sur le maillage.
Et hop :

Une fois fait je test une seconde page pour voir la pertinence des suggestions sur l’url https://protealpes.com/whey-boxe/
C’est déjà mieux que la première fois, on imagine bien un lien depuis la page comment choisir sa whey ou encore depuis des recettes un peu spécifiques.

Néanmoins je trouve la pertinence encore assez limitée et pour beaucoup de suggestions il me parait ardu d’intégrer des liens naturellement.
C’est dommage car pour cet exemple par exemple les boxeurs enchaînent les phases de prises de masse contrôlées et les sèches avant compétitions, il y a donc beaucoup à dire sur ces périodes spéciales pour l’athlète et les sujets sont largement traités sur le blog.
Encore une fois, je ne connais pas leur méthodologie donc je ne leur jette pas la pierre.
Par contre il serait intéressant d’avoir des pistes sur les raisons qui ont poussé l’algo à choisir telle ou telle page et ce qui constitue ce score.
Niveau pertinence, notez que cette fois Thot est tout autant en carafe.

Pour celle-ci, je vais prendre quelques idées dans les suggestions et faire un petit maillage entre toutes mes pages “whey pour [sport au choix] ”
Passons maintenant à l’option de maillage interne vers des pages stratégiques.
Déjà première bonne surprise on nous prévient quand une page a déjà un nombre important de liens ! 🎉

Pour le test je vais poursuivre avec cette URL et voir ce qu’il en ressort.
Effectivement, on ne voit aucune suggestion car toutes les pages font déjà un lien vers celle-ci via le menu.
Néanmoins on voit qu’il n’y a qu’une ancre parmi ces 201 liens internes entrants !

💡 Idée d’améliroation : Niveau UX j’ai failli passer à côté, personnellement j’aurais mis en vert la partie concernant le nombre de liens mais dans un encadré rouge la partie concernant la diversité des ancres.
Pour diversifier les ancres vers cette page je vais simplement aller dans la Search Console pour identifier les termes avec le plus de potentiels.
Enfin, nous allons tester les pages qui peuvent nous être conseillées.
Bon, on le voit juste après mais comme j’ai obfusqué certains liens du footer entre le premier et le second audit la première page suggérée n’est pas très pertinente.
Il devrait être assez simple de mettre une règle pour éliminer ces pages assez communes.

La suivante et beaucoup plus intéressante : peu d’ancres, peu de liens, gros potentiel d’après les impressions, let’s try !
Arg, on ne peut en lancer qu’une seule à la fois, c’est dommage étant donné que j’ai quand même une centaine de pages à remailler…
Au passage, une fois sur l’analyse ce rappel en bleu est vraiment utile ! En revanche le nombre de liens ajoutés recommandés ne semble pas s’ajuster en fonction du nombre de liens internes car si j’ajoute les 10 aux 2 déjà présent je suis au dessus du minimum de 11 cités dans l’audit et bien au dessus des 5 liens conseillés dans l’encart bleu.

Concernant les suggestions, même retour, je passe donc à la suite.
En jetant un œil à mon Google Sheet issu du premier audit on se rend compte que, comme d’habitude, les pages contact mentions légales et autres pages obligatoires reçoivent énormément de liens.

On voit aussi qu’avec la refonte les nouvelles pages produits ne reçoivent pas beaucoup d’ancres différentes !
Mais un problème à la fois, pour l’instant concentrons nous sur les pages qui n’ont pas de vocation SEO.
Pour éviter d’aller accumuler du PR interne dans ces zones j’ai décidé d’obfusquer à minima les liens du footer.
J’indique par une flèche rouge les seuls que j’ai laissés en lien classique :

Pour cela c’est assez simple, tout est expliqué sur l’article de 410 Gone. Leur méthode est carrée et c’est celle que je recommande.
En bref, on va utiliser du Javascript pour masquer certains liens qu’on aura encodé en Base64.
Résultat les pages comme « notre expertise » ou « notre histoire » sont toujours trop pleines, mais moins. A l’occasion il faudra exploiter valeurs, histoires et autres pour faire des liens vers les pages stratégiques.

Je pense que vous avez compris ma méthodologie, je vais donc conclure cette partie maillage interne. En résumé :
- Je sélectionne une page à laquelle il manque des liens internes ou des ancres variées ;
- Je trouve des pages depuis lesquelles faire des liens avec RM Console et Thot ;
- Je prends des ancres non utilisées en vérifiant via ScreamingFrog ou mon Google Sheet ;
- J’implémente naturellement les liens dans les paragraphes.
Maintenant qu’on en a terminé avec le maillage interne (ouf) passons à la partie suivante :
Balise title (ou plutôt title tag si on veut être précis)
C’est un élément crucial donc ça mérite notre attention.
Ici on va observer :
- Taille de la balise Title Doublons dans la balise title
- Répétition de mots dans la balise Title
RM Tech fait ça plutôt bien, pas de fioritures : on liste les problèmes et ce qui serait le top.
Pour finir on a la conclusion sur cet aspect avec ici 28% d’erreur.

J’aurais apprécié un doc Excel téléchargeable avec toutes les erreurs pour chaque URL mais bon fusionner les 3 Excel disponibles ne prend pas trop de temps (moins de 2 minutes).
Voilà le résultat qu’il va encore nous falloir filtrer pour retirer les pages que l’on a retiré de l’index dans le début de cette mission :

Après filtrage il nous reste 39 pages avec un problème, plus aucun souci de doublon.

Je ne vais pas m’étendre trop sur cette partie car vous vous doutez de l’exercice.
Il ne s’agit surtout pas de corriger le problème artificiellement mais bien de reprendre ces balises avec une vision business.
Vous vous en doutez, ce n’est pas de supprimer le mot “et” de votre title tag pour passer de 72 à 70 caractères qui va propulser votre page en top SERP mais pour l’exercice on va viser 70 caractères max tout pile.
J’insiste sur ce point, ici je modifie le site pour améliorer le score RM Tech, pas seulement obtenir plus de trafic.
Dans cette optique j’ai des actions de corrections qui ne sont pas forcément très logiques niveau ROI. Par exemple le temps que je passe à modifier le title tag de la page du programme de fidélité n’est probablement pas très utile.
Voici 2 exemples de changement de title :
- Ancien title tag : Whey Fraise – Protéalpes
- Nouveau title tag : Whey Fraise – Protéines en poudre sans additifs et sans édulcorants Protéalpes
- Ancien : Whey Protein
- Nouveau : Whey Protein Française – Sans Édulcorants et Sans Additifs (6 goûts)
Pour m’aider j’aime utiliser Thot qui combine le nombre de caractères mais aussi des indications concernant les mots utilisés par mes concurrents.

Après 30 minutes environ toutes les pages nécessitant une reprise sont à jour, il ne reste plus que les pages catégories générées par Woo Commerce.
Elles ne sont pas éditables en l’état sans modifier ce qui est affiché sur le site et comme elles vont être remaniées autant ne pas perdre de temps à modifier le thème pour 4 pages.
Passons à la suite.
Balise méta description
Attaquons la 6ème catégorie technique proposée par RM Tech : l’audit des meta descriptions.
Bien qu’il y ait de quoi faire des memes sur les “experts” SEO qui passent 5 jours à éditer ces balises sur un site, les meta descriptions conservent un peu d’importance.
Bien copywritées elles peuvent augmenter le CTR et d’un point de vue plus personnel je pense qu’elles restent importantes pour décrire une page quand on propose une approche ou un format différent du reste de la SERP.
Ici RM Tech conserve le même format en listant les erreurs de tailles et les doublons.

Vous connaissez la musique :
- Je télécharge les fichiers Excel ;
- Je les fusionne sur mon GGSheet de travail ;
- Je filtre les pages stratégiques puis j’attaque le chantier
Résultat on a 140 pages problématiques notamment à cause des divi_shortcode qui ne fonctionnent pas.

Pensant que ces shortcodes n’étaient plus maintenus et voulant aller rapidement sur ce point j’ai tenté un script en PHP qui remplace les meta-descriptions automatiquement.
Si vous ne codez pas, ce code sert simplement à construire une meta-description ainsi :
Titre du produit + ‘par ProtéAlpes. Sans additifs, sans édulcorants et made in France ! Certifié sans substances dopantes et sans gluten. Plusieurs saveurs et plusieurs packs disponibles. Produits développés par des pharmaciens pour les athlètes en quête de performance.’
function update_short_descriptions_of_products() {
global $wpdb;
$products = $wpdb->get_results("SELECT ID, post_title FROM $wpdb->posts WHERE post_type = 'product'", ARRAY_A);
foreach ($products as $product) {
$new_text = ' par ProtéAlpes. Sans additifs, sans édulcorants et made in France 🇫🇷 ! Certifié sans substances dopantes et sans gluten. Plusieurs saveurs et plusieurs packs disponibles. Produits développés par des pharmaciens pour les athlètes en quête de performance.';
$new_description = $product['post_title'] . $new_text;
$wpdb->update(
$wpdb->posts,
array('post_excerpt' => $new_description),
array('ID' => $product['ID'])
);
}
}
update_short_descriptions_of_products();Les post_excerpt ont bien été modifiés seulement ces éléments étaient utilisés par woo-commerce comme description courte des produits.
En bref, avant tous les produits avaient une description propre comme ceci :

Et après ma boulette 100% des produits ressemblaient à cela :

Évidemment je n’avais pas prévu de sauvegarde de la base de données et j’ai dû reprendre les descriptions une à une en urgence alors que j’avais la soirée de départ de mon coloc médecin pour le Togo…
Conclusion de cette opération, environ 2h pour réparer ma bourde et 45 minutes pour modifier les meta-descriptions à la main avec l’aide de chat GPT.
Paaaaartie suivante :
Liens sortants en erreur
Ici, RM Tech nous permet d’exporter un tableau super actionnable un peu similaire à ce qu’on obtient via l’export des liens externes de Screaming Frog.
Il ne nous faut plus que filtrer les codes HTTP de l’url de destination qui ne sont pas en 200 et traiter les problèmes un à un.
Honnêtement via le plugin Worpress de Better Search And Replace cela prend moins de 10 minutes pour les 15 liens identifiés.

C’est donc très bien diagnostiqué par la solution.
Rapidement traité, next !
Les titres Hn
Les titres peuvent engendrer de très nombreux problèmes, voici ceux listés par RM Tech :
- H1 absente
- Que des H1 vides
- Au moins une H1 vide
- 1ère balise Hn n’est pas H1 Sauts de niveau entre les Hn
- Hn trop longues (> 80 caractères) Nb de H1 trop nombreux
- 1 seule balise H2-H6
- Même libellé dans plusieurs Hn Même libellé dans H1 et Title
Quand on exporte le résultat sur notre GGSheet voici ce que cela peut donner comme espace de travail.

Heureusement l’équipe de RM Tech ne lésine pas sur les explications et nous donne plusieurs détails importants, notamment la distinction entre erreurs et avertissements.
Pour les erreurs on a uniquement :
- Plus de 1 titre H1 par page (hors page d’accueil)
- une balise H1 ne peut pas être vide
Je vais me concentrer sur ces deux éléments ainsi que la présence de la H1 en première balise et les Hn trop longues.
Petit point sur l’export des Hn, le document est ultra complet, presque décourageant à vrai dire quand on arrive dessus et qu’on voit la charge de travail.
Pourtant avoir une distinction dans les colonnes de ce qui est une erreur ou un avertissement pour éviter ce découragement :

Je regrette aussi de ne pas avoir une seconde page permettant de gagner du temps sur l’identification précise du problème.
Par exemple :
- 1ère balise Hn n’est pas H1 → indiquer ce que c’est (balise + intitulé)
- Sauts de niveau entre les Hn → indiquer les sauts problématiques
- Hn trop longues → indiquer le Hn concerné et l’intitulé + la taille
- Même libellé dans plusieurs Hn → libellé concerné
Cela dit c’est bien plus complet que ce que nous propose screaming frog en basique et on gagne quand même un temps important.
Passons à la correction :
Pour vous donner une idée en comptant les espaces cette balise fait 88 caractères : Quels édulcorants peuvent être dans vos protéines en poudre / quels édulcorants éviter ?
Pour les identifier c’est très simple via Screaming Frog via la regex <h[1-6]>[^<]{75,}</h[1-6]> (adaptez 75 à la longueur que vous jugez trop importante) :

Après un crawl on a la liste des URLs concernées et on peut décider d’agir ou non en un coup d’oeil :

Finalement après vérification il n’y a rien d’alarmant.
Certaines balises sont effectivement un peu longues mais rien de dramatique qui serait lié à une erreur technique.
Concernant les avertissements (le reste donc) tout ne sera pas corrigé car cela prendrait bien trop de temps pour un gain SEO assez faible.
Néanmoins tous les conseils sont ultra pertinents et si vous débuter la création d’un site ils sont à vraiment avoir en tête :
la 1ère balise d’une page doit être une H1
il faut éviter les sauts de niveau : quand il s’agit de descendre dans les détails, une balise Hn ne peut être suivie que par une balise H(n+1) dans l’ordre du code source, mais pas H(n+2) ou H(n+3) : on ne doit pas sauter de niveau. Par exemple, après une H1, il ne peut y avoir qu’une H2. Après une H3, il ne peut y avoir qu’une H4 (ou bien une autre H3, ou bien on remonte et c’est une H2), mais pas une H5.
la taille d’une balise Hn (nb de caractères) ne doit pas dépasser 80 caractères (même si ce chiffre est arbitraire, fixé selon notre expérience, l’idée est qu’un titre doit rester un titre et non un paragraphe)
il est recommandé de limiter à 1 le nombre de balises H1 par page
pour les balises H2-H6 « isolées » : dans un niveau donné, le nombre de titres du niveau inférieur doit être 0 ou au moins 2 (donc pas seulement 1). La raison est que si vous utilisez une balise H2 (ou H3, H4, H5, H6), c’est a priori pour découper en plusieurs sous-parties le bloc de niveau supérieur. Il doit donc y en avoir soit aucune, soit au moins 2 dans une page.
dans la mesure du possible, il faut éviter d’utiliser un même libellé dans plusieurs balises H1-H6 d’une même page
Source : Audit RM Tech par Fabien et Olivier
Parmi les problèmes on a ceux assez classiques des H1 utilisés pour gérer la taille de police comme ici pour un encart en bas de page :

Pour remplacer les balises H1 vident une technique rapide via notre plugin de modification de la base de données :

Ensuite une part importante des problématiques de titres peut être gérée via des changements sur le thème directement.
Par exemple sur Woo Commerce il semblerait que par défaut le nom des produits soit en H2, il suffit de le modifier dans le thème (ici sur Divi).

Une fois cela terminé, notre tableau est désormais corrigé sur les points principaux !

Passons au contenu, une des pierres angulaires d’une stratégie SEO.
Le contenu : quels sont les problèmes potentiels ?
RM Tech nous propose aussi une liste des pages qui ont peut de contenu pour identifier celles qui risque de ne par répondre pleinement aux internautes, le fameux thin content que l’on cherche à éviter.
Dans la dernière grande étude de Thot SEO, l’analyse de plus de 20 000 contenus montrait que le nombre de mots était un très mauvais indicateur de position. Pour les SERPs informationelles le nombre de mots d’un contenu semble n’avoir aucun impact sur les positions du top 3 et un impact limité sur les positions 4 à 8.
C’est également un très mauvais prédicteur pour les positions 1 à 3 de courte et longue traine des SERP commerciales. Cependant, 500 mots semble être une condition quasiment sine qua non pour évoluer au sein du top 4 à 8.
Bon, même s’il est vrai qu’une page avec un contenu texte court est rarement de nature à satisfaire tous les internautes il y a des exceptions.
Heureusement la majorité des pages identifiées par l’algo RM Tech rentrent dans la catégorie des pages qui n’ont pas besoin de faire 18 pieds de longs pour remplir leur rôle (les pages sur l’histoire de l’entreprise, le blog, les revendeurs, les athlètes sponsorisés… )

Je note que l’algo doit avoir un tout petit souci pour extraire le contenu des pages qui sont composées à 100% de liens car la page de questions fréquentes (générée automatiquement) fait déjà plus de 2000 mots (uniquement des liens).
Pour les pages recettes j’ai enrichi celles concernées par des informations sur la conservation et quelques conseils nutritionnels comme cela :

Pour les pages catégories qui n’ont pas forcément d’enjeux SEO j’ai simplement ajouté une FAQ la plus utile possible à l’internaute soucieux d’en savoir plus, sans forcément chercher à l’optimiser en outre mesure.

L’audit se termine par une analyse plus avancée en incluant les indices propres à RM Tech :
Indices Quality Risk et pages Zombies
Ici j’ai simplement fusionné en 3 colonnes toutes les données intéressantes et filtrer les URLs qui n’ont pas un score inférieur à 20 sur les deux indices.
Résultat 114 pages à traiter ! Cela peut paraître énorme mais au vu du travail déjà effectué je pense qu’une bonne partie a été réglée.

Comme je ne sais pas exactement comment corriger chaque page pour les sortir de leur Quality Risk ou de leur état de Zombie je vais simplement les observer une à une et tenter de faire preuve de bon sens.
Personnellement je trouve qu’il manque un moyen simple de contrôler chaque URL individuellement sans relancer un audit. Cette solution pourrait d’ailleurs être une version gratuite pour pousser les consultants et webmasters sérieux à prendre l’analyse complète du site.
Conclusion
L’outil est ultra complet, il peut faire peur aux non initiés mais honnêtement les explications sont toujours très limpides. Au pire le support est vraiment réactif.
Globalement, je note que les données sont bien exploitées et les suggestions très actionnables.
L’UX est probablement le premier point de réelle amélioration selon moi, en tout cas si RM Tech veut diffuser son outil à des webmasters moins habitués au jargon technique du SEO.
Ensuite le second point concerne la pertinence des suggestions de pages par le module maillage interne. Il y a encore pas mal de tri à faire mais je pense que cela ira de mieux en mieux car la fonctionnalité n’a que quelques mois. La méthodologie n’a pas à être ultra compliquée pour gagner en pertinence.
En tout cas, pour sa mission de faire parler les données : c’est validé. On gagne un temps fou sur le diagnostic et on dégage du temps pour l’implémentation.
Concernant le pricing je trouve cela plutôt bien adapté à la valeur délivrée pour les consultants ou les propriétaires de site.
Alors oui, à part le diagnostic des pages zombies et ou du quality risk pour lesquels nous n’avons pas les formules, rien n’est infaisable en solo dans son coin en couplant la search console à un script python ou à screaming frog mais on y passerait un temps très important et on y gagnerait pas forcément en qualité de recommendations.
J’attends de voir l’impact sur les positions mais toutes les suggestions paraissent plus que pertinentes et j’ai hâte de l’utiliser sur de nouveaux cas.
Pour ce type de e-commerce (<500 pages), suivant la fréquence de modifications du site je pense qu’un audit automatique tous les 15 à 30 jours est intéressant pour lisser la charge de travail et éviter l’accumulation des mauvaises pratiques longues à traiter.
Et les résultats ?
Vous le savez aussi bien que moi, les résultats SEO prennent du temps.
Je modifierai cet article dès que les semaines d’observation seront passées et qu’on aura un aperçu des résultats concrets sur le trafic.
J’ai également un nouvel audit de prévu sous peu pour voir l’évolution des scores pour vous illustrer l’impat de ces modifications. Je pense atteindre au moins 90 sur les deux scores avec cette première salve de modifications.